Enumerable is a collection of iteration methods, a Ruby module, and a big part of what makes Ruby a great programming language.
# count elements that evaluate to true inside a block
[1,2,34].count
=> 3
# Group enumerable elements by the block return value. Returns a hash
[12,3,7,9].group_by {|x| x.even? ? 'even' : 'not_even'}
=> {"even" => [12], "not_even" => [3, 7, 9]}
# Partition into two groups. Returns a two-dimensional array
> [1,2,3,4,5].partition { |x| x.even? }
=> [[2, 4], [1, 3, 5]]
# Returns true if the block returns true for ANY elements yielded to it
> [1,2,5,8].any? 4
=> false
> [1,2,5,8].any? { |x| x.even?}
=> true
# Returns true if the block returns true for ALL elements yielded to it
> [2,5,6,8].all? {|x| x.even?}
=> false
# Opposite of all?
> [2,2,5,7].none? { |x| x.even?}
=> false
# Repeat ALL the elements n times
> [3,4,6].cycle(3).to_a
=> [3, 4, 6, 3, 4, 6, 3, 4, 6]
# select - SELECT all elements which pass the block
> [18,4,5,8,89].select {|x| x.even?}
=> [18, 4, 8]
> [18,4,5,8,89].select(&:even?)
=> [18, 4, 8]
# Like select, but it returns the first thing it finds
> [18,4,5,8,89].find {|x| x.even?}
=> 18
# Accumulates the result of the previous block value & passes it into the next one. Useful for adding up totals
> [4,5,8,90].inject(0) { |x, sum| x + sum }
=> 107
> [4,5,8,90].inject(:+)
=> 107
# Note that 'reduce' is an alias of 'inject'.
# Combines together two enumerable objects, so you can work with them in parallel. Useful for comparing elements & for generating hashes
> [2,4,56,8].zip [3,4]
=> [[2, 3], [4, 4], [56, nil], [8, nil]]
# Transforms every element of the enumerable object & returns the new version as an array
> [3,6,9].map { |x| x+89-27/2*23 }
=> [-207, -204, -201]
What is :+ in [4, 5, 8, 90].inject(:+) in Ruby?
🔣 :+ is a Symbol representing the + method.
In Ruby, every operator (like +, *, etc.) is actually a method under the hood.
inject takes a symbol (:+)
Ruby calls .send(:+) on each pair of elements
It’s equivalent to: (((4 + 5) + 8) + 90) => 107
🔣 &: Explanation:
:even? is a symbol representing the method even?
&: is Ruby’s “to_proc” shorthand, converting a symbol into a block
Loops are an essential part of any programming language—they allow developers to execute code repeatedly without redundant repetition. Ruby, being an elegant and expressive language, offers several ways to implement looping constructs. This blog post explores Ruby loops through a real-world case study and demonstrates best practices for choosing the right loop for the right situation.
🧠 Why Loops Matter in Ruby
In Ruby, loops help automate repetitive tasks and iterate over collections (arrays, hashes, ranges, etc.). Understanding the different loop types and their use cases will help you write more idiomatic, efficient, and readable Ruby code.
🧪 The Case Study: Daily Sales Report Generator
Imagine you’re building a Ruby application for a retail store (like our Design studio) that generates a daily sales report. Your data source is an array of hashes, where each hash represents a sale with attributes like product name, category, quantity, and revenue.
Takeaway: Prefer Enumerable methods like select, map, reduce when working with collections. Loops are useful, but Ruby’s functional approach often leads to cleaner code.
✅ Summary Table: Ruby Loops at a Glance
Loop Type
Scope-safe
Index Access
Best Use Case
each
✅
❌
Simple iteration
each_with_index
✅
✅
Need both element and index
for
❌
✅
Familiar syntax, but avoid in idiomatic Ruby
while
✅
✅ (manual)
When condition is external
until
✅
✅ (manual)
Inverted while, clearer for some logic
loop do + break
✅
✅ (manual)
Controlled infinite loop
🏁 Conclusion
Ruby offers a wide range of looping constructs. This case study demonstrates how to choose the right one based on context. For most collection traversals, each and other Enumerable methods are preferred. Use while, until, or loop when finer control over the iteration process is required.
Loop mindfully, and let Ruby’s elegance guide your code.
When you create a brand-new Rails 8 project today you automatically get a super-powerful front-end toolbox called Hotwire.
Because it is baked into the framework, it can feel a little magical (“everything just works!”). This post demystifies Hotwire, shows how its two core libraries—Turbo and Stimulus—fit together, and then walks through the places where the design_studio codebase is already using them.
1. What is Hotwire?
Hotwire (HTML Over The Wire) is a set of conventions + JavaScript libraries that lets you build modern, reactive UIs without writing (much) custom JS or a separate SPA. Instead of pushing JSON to the browser and letting a JS framework patch the DOM, the server sends HTML fragments over WebSockets, SSE, or normal HTTP responses and the browser swaps them in efficiently.
Hotwire is made of three parts:
Turbo – the engine that intercepts normal links/forms, keeps your page state alive, and swaps HTML frames or streams into the DOM at 60fps.
Stimulus – a “sprinkle-on” JavaScript framework for the little interactive bits that still need JS (dropdowns, clipboard buttons, etc.).
(Optional) Strada – native-bridge helpers for mobile apps; not relevant to our web-only project.
Because Rails 8 ships with both turbo-rails and stimulus-rails gems, simply creating a project wires everything up.
2. How Turbo & Stimulus complement each other
Turbo keeps pages fresh – It handles navigation (Turbo Drive), partial page updates via <turbo-frame> (Turbo Frames), and real-time broadcasts with <turbo-stream> (Turbo Streams).
Stimulus adds behaviour – Tiny ES-module controllers attach to DOM elements and react to events/data attributes. Importantly, Stimulus plays nicely with Turbo’s DOM-swapping because controllers automatically disconnect/re-connect when elements are replaced.
Think of Turbo as the transport layer for HTML and Stimulus as the behaviour layer for the small pieces that still need JavaScript logic.
# server logs - still identify as HTML request, It handles navigation through (Turbo Drive)
Started GET "/products/15" for ::1 at 2025-06-24 00:47:03 +0530
Processing by ProductsController#show as HTML
Parameters: {"id" => "15"}
.......
Started GET "/products?category=women" for ::1 at 2025-06-24 00:50:38 +0530
Processing by ProductsController#index as HTML
Parameters: {"category" => "women"}
.......
Javascript and css files that loads in our html head:
As soon as that file is imported (it’s linked in application.html.erb via javascript_include_tag "application", "data-turbo-track": "reload" ), Turbo intercepts every link & form on the site.
3.3 Stimulus controllers
The framework-generated controller registry lives at app/javascript/controllers/index.js; the only custom controller so far is the hello-world example:
You can drop new controllers into app/javascript/controllers/anything_controller.js and they will be auto-loaded thanks to the pin_all_from line above.
Turbo receives the <turbo-stream> tag, finds the element with that id, and removes it from the DOM—no page reload, no hand-written JS.
# app/views/products/show.html.erb
....
<%= link_to @product,
data: { turbo_method: :delete, turbo_confirm: "Are you sure you want to delete this product?" },
class: "px-4 py-2 bg-red-500 text-white rounded-lg hover:bg-red-600 transition-colors duration-200" do %>
<i class="fas fa-trash mr-2"></i>Delete Product
<% end %>
....
3.5 “Free” Turbo benefits you might not notice
Because Turbo Drive is on globally:
Standard links look instantaneous (HTML diffing & cache).
Form submissions automatically request .turbo_stream when you ask for format.turbo_stream in a controller.
Redirects keep scroll position/head tags in sync.
All of this happens without any code in the repo—Rails 8 + Turbo does the heavy lifting.
4. Extending Hotwire in the future
More Turbo Frames – Wrap parts of pages in <turbo-frame id="cart"> to make only the cart refresh on “Add to cart”.
Broadcasting – Hook Product model changes to turbo_stream_from channels so that all users see live stock updates.
Stimulus components – Replace jQuery snippets with small controllers (dropdowns, modals, copy-to-clipboard, etc.).
Because everything is wired already (Importmap, controller autoloading, Cable), adding these features is mostly a matter of creating the HTML/ERB templates and a bit of Ruby.
Questions
1. Is Rails 8 still working with the real DOM?
Yes, the browser is always working with the real DOM—nothing is virtualized (unlike React’s virtual DOM).
Turbo intercepts navigation events (links, form submits). Instead of letting the browser perform a “hard” navigation, it fetches the HTML with fetch() in the background, parses the response into a hidden document fragment, then swaps specific pieces (usually the whole <body> or a <turbo-frame> target) into the live DOM.
Because Turbo only swaps the changed chunks, it keeps the rest of the page alive (JS state, scroll position, playing videos, etc.) and fires lifecycle events so Stimulus controllers disconnect/re-connect cleanly.
“Stimulus itself is a tiny wrapper around MutationObserver. It attaches controller instances to DOM elements and tears them down automatically when Turbo replaces those elements—so both libraries cooperate rather than fighting the DOM.”
2. How does the HTML from Turbo Drive get into the DOM without a full reload?
Step-by-step for a normal link click:
turbo-rails JS (loaded via import “@hotwired/turbo-rails”) cancels the browser’s default navigation.
Turbo sends an AJAX request (actually fetch()) for the new URL, requesting full HTML.
The response text is parsed into an off-screen DOMParser document.
Turbo compares the <head> tags, updates <title> and any changed assets, then replaces the <body> of the current page with the new one (or, for <turbo-frame>, just that frame).
It pushes a history.pushState entry so Back/Forward work, and fires events like turbo:load.
Because no real navigation happened, the browser doesn’t clear JS state, WebSocket connections, or CSS; it just swaps some DOM nodes—visually it feels instantaneous.
3. What does pin mean in config/importmap.rb?
Rails 8 ships with Importmap—a way to use normal ES-module import statements without a bundler.pin is simply a mapping declaration:
pin "@hotwired/turbo-rails", to: "turbo.min.js"
pin "@hotwired/stimulus", to: "stimulus.min.js"
Meaning:
When the browser sees import "@hotwired/turbo-rails", fetch …/assets/turbo.min.js
When it sees import “controllers”, look at pin_all_from "app/javascript/controllers" which expands into individual mappings for every controller file.
Think of pin as the importmap equivalent of a require statement in a bundler config—just declarative and handled at runtime by the browser. That’s all there is to it: real DOM, no page reloads, and a lightweight way to load JS modules without Webpack.
Take-aways
Hotwire is not one big library; it is a philosophy (+ Turbo + Stimulus) that keeps most of your UI in Ruby & ERB but still feels snappy and modern.
Rails 8 scaffolds everything, so you may not even realize you’re using it—but you are!
design_studio already benefits from Hotwire’s defaults (fast navigation) and uses Turbo Streams for dynamic image deletion. The plumbing is in place to expand this pattern across the app with minimal effort.
Ever wondered what happens when Sidekiq calls redis.brpop() and your thread magically “blocks” until a job appears? The answer lies in one of computing’s most fundamental concepts: sockets. Let’s dive deep into this invisible infrastructure that powers everything from your Redis connections to Netflix streaming.
🚀 What is a Socket?
A socket is essentially a communication endpoint – think of it like a “phone number” that programs can use to talk to each other.
Application A ←→ Socket ←→ Network ←→ Socket ←→ Application B
Simple analogy: If applications are people, sockets are like phone numbers that let them call each other!
🎯 The Purpose of Sockets
📡 Inter-Process Communication (IPC)
# Two Ruby programs talking via sockets
# Program 1 (Server)
require 'socket'
server = TCPServer.new(3000)
client_socket = server.accept
client_socket.puts "Hello from server!"
# Program 2 (Client)
client = TCPSocket.new('localhost', 3000)
message = client.gets
puts message # "Hello from server!"
Ports are like apartment numbers – they help identify which specific application should receive the data.
IP Address: 192.168.1.100 (Building address)
Port: 6379 (Apartment number)
🎯 Why This Matters
Same computer running:
- Web server on port 80
- Redis on port 6379
- SSH on port 22
- Your app on port 3000
When data arrives at 192.168.1.100:6379
→ OS knows to send it to Redis
🏢 Why Do We Need So Many Ports?
Think of a computer like a massive apartment building:
🔧 Multiple Services
# Different services need different "apartments"
$ netstat -ln
tcp 0.0.0.0:22 SSH server
tcp 0.0.0.0:80 Web server
tcp 0.0.0.0:443 HTTPS server
tcp 0.0.0.0:3306 MySQL
tcp 0.0.0.0:5432 PostgreSQL
tcp 0.0.0.0:6379 Redis
tcp 0.0.0.0:27017 MongoDB
🔄 Multiple Connections to Same Service
Redis server (port 6379) can handle:
- Connection 1: Sidekiq worker
- Connection 2: Rails app
- Connection 3: Redis CLI
- Connection 4: Monitoring tool
Each gets a unique "channel" but all use port 6379
# What happens when you do this:
socket = TCPSocket.new('localhost', 6379)
Behind the scenes:
// OS system calls
socket_fd = socket(AF_INET, SOCK_STREAM, 0) // Create socket
connect(socket_fd, server_address, address_len) // Connect
📋 The OS Socket Table
Process ID: 1234 (Your Ruby app)
File Descriptors:
0: stdin
1: stdout
2: stderr
3: socket to Redis (localhost:6379)
4: socket to PostgreSQL (localhost:5432)
5: listening socket (port 3000)
🔮 Kernel-Level Magic
Application: socket.write("PING")
↓
Ruby: calls OS write() system call
↓
Kernel: adds to socket send buffer
↓
Network Stack: TCP → IP → Ethernet
↓
Network Card: sends packets over wire
🌈 Types of Sockets
📦 TCP Sockets (Reliable)
# Like registered mail - guaranteed delivery
server = TCPServer.new(3000)
client = TCPSocket.new('localhost', 3000)
# Data arrives in order, no loss
client.write("Message 1")
client.write("Message 2")
# Server receives exactly: "Message 1", "Message 2"
⚡ UDP Sockets (Fast but unreliable)
# Like shouting across a crowded room
require 'socket'
# Sender
udp = UDPSocket.new
udp.send("Hello!", 0, 'localhost', 3000)
# Receiver
udp = UDPSocket.new
udp.bind('localhost', 3000)
data = udp.recv(1024) # Might not arrive!
🏠 Unix Domain Sockets (Local)
# Super fast local communication
File.delete('/tmp/test.sock') if File.exist?('/tmp/test.sock')
# Server
server = UNIXServer.new('/tmp/test.sock')
# Client
client = UNIXSocket.new('/tmp/test.sock')
🔄 Socket Lifecycle
🤝 TCP Connection Dance
# 1. Server: "I'm listening on port 3000"
server = TCPServer.new(3000)
# 2. Client: "I want to connect to port 3000"
client = TCPSocket.new('localhost', 3000)
# 3. Server: "I accept your connection"
connection = server.accept
# 4. Both can now send/receive data
connection.puts "Hello!"
client.puts "Hi back!"
# 5. Clean shutdown
client.close
connection.close
server.close
🔄 Under the Hood (TCP Handshake)
Client Server
| |
|---- SYN packet -------->| (I want to connect)
|<-- SYN-ACK packet ------| (OK, let's connect)
|---- ACK packet -------->| (Connection established!)
| |
|<---- Data exchange ---->|
| |
🏗️ OS-Level Socket Implementation
📁 File Descriptor Magic
socket = TCPSocket.new('localhost', 6379)
puts socket.fileno # e.g., 7
# This socket is just file descriptor #7!
# You can even use it with raw system calls
socket.write("BRPOP queue 0")
# 1. Ruby copies data to kernel send buffer
# 2. write() returns immediately
# 3. Kernel sends data in background
# 4. TCP handles retransmission, etc.
What happens on socket.read:
data = socket.read
# 1. Check kernel receive buffer
# 2. If empty, BLOCK thread until data arrives
# 3. Copy data from kernel to Ruby
# 4. Return to your program
🎯 Real-World Example: Sidekiq + Redis
# When Sidekiq does this:
redis.brpop("queue:default", timeout: 2)
# Here's the socket journey:
# 1. Ruby opens TCP socket to localhost:6379
socket = TCPSocket.new('localhost', 6379)
# 2. Format Redis command
command = "*4\r\n$5\r\nBRPOP\r\n$13\r\nqueue:default\r\n$1\r\n2\r\n"
# 3. Write to socket (goes to kernel buffer)
socket.write(command)
# 4. Thread blocks reading response
response = socket.read # BLOCKS HERE until Redis responds
# 5. Redis eventually sends back data
# 6. Kernel receives packets, assembles them
# 7. socket.read returns with the job data
🚀 Socket Performance Tips
♻️ Socket Reuse
# Bad: New socket for each request
100.times do
socket = TCPSocket.new('localhost', 6379)
socket.write("PING\r\n")
socket.read
socket.close # Expensive!
end
# Good: Reuse socket
socket = TCPSocket.new('localhost', 6379)
100.times do
socket.write("PING\r\n")
socket.read
end
socket.close
🏊 Connection Pooling
# What Redis gem/Sidekiq does internally
class ConnectionPool
def initialize(size: 5)
@pool = size.times.map { TCPSocket.new('localhost', 6379) }
end
def with_connection(&block)
socket = @pool.pop
yield(socket)
ensure
@pool.push(socket)
end
end
🎪 Fun Socket Facts
📄 Everything is a File
# On Linux/Mac, sockets appear as files!
$ lsof -p #{Process.pid}
ruby 1234 user 3u sock 0,9 0t0 TCP localhost:3000->localhost:6379
🚧 Socket Limits
# Your OS has limits
$ ulimit -n
1024 # Max file descriptors (including sockets)
# Web servers need thousands of sockets
# That's why they increase this limit!
🔌 Sockets = Communication endpoints between programs
🏠 Ports = Apartment numbers for routing data to the right app
🌐 Not just networking – also local inter-process communication
⚙️ OS manages everything – kernel buffers, network stack, blocking
📁 File descriptors – sockets are just special files to the OS
🏊 Connection pooling is crucial for performance
🔒 BRPOP blocking happens at the socket read level
🌟 Conclusion
The beauty of sockets is their elegant simplicity: when Sidekiq calls redis.brpop(), it’s using the same socket primitives that have powered network communication for decades!
From your Redis connection to Netflix streaming to Zoom calls, sockets are the fundamental building blocks that make modern distributed systems possible. Understanding how they work gives you insight into everything from why connection pooling matters to how blocking I/O actually works at the system level.
The next time you see a thread “blocking” on network I/O, you’ll know exactly what’s happening: a simple socket read operation, leveraging decades of OS optimization to efficiently wait for data without wasting a single CPU cycle. Pretty amazing for something so foundational! 🚀
⚡ Inside Redis: How Your Favorite In-Memory Database Actually Works
You’ve seen how Sidekiq connects to Redis via sockets, but what happens when Redis receives that BRPOP command? Let’s pull back the curtain on one of the most elegant pieces of software ever written and discover why Redis is so blazingly fast.
🎯 What Makes Redis Special?
Redis isn’t just another database – it’s a data structure server. While most databases make you think in tables and rows, Redis lets you work directly with lists, sets, hashes, and more. It’s like having super-powered variables that persist across program restarts!
# Traditional database thinking
User.where(active: true).pluck(:id)
# Redis thinking
redis.smembers("active_users") # A set of active user IDs
🏗️ Redis Architecture Overview
Redis has a deceptively simple architecture that’s incredibly powerful:
┌─────────────────────────────────┐
│ Client Connections │ ← Your Ruby app connects here
├─────────────────────────────────┤
│ Command Processing │ ← Parses your BRPOP command
├─────────────────────────────────┤
│ Event Loop (epoll) │ ← Handles thousands of connections
├─────────────────────────────────┤
│ Data Structure Engine │ ← The magic happens here
├─────────────────────────────────┤
│ Memory Management │ ← Keeps everything in RAM
├─────────────────────────────────┤
│ Persistence Layer │ ← Optional disk storage
└─────────────────────────────────┘
// Simplified Redis main loop
while (server_running) {
// 1. Check for new network events
events = epoll_wait(eventfd, events, max_events, timeout);
// 2. Process each event
for (int i = 0; i < events; i++) {
if (events[i].type == READ_EVENT) {
process_client_command(events[i].client);
}
}
// 3. Handle time-based events (expiry, etc.)
process_time_events();
}
Why single-threaded is brilliant:
✅ No locks or synchronization needed
✅ Incredibly fast context switching
✅ Predictable performance
✅ Simple to reason about
🧠 Data Structure Deep Dive
📝 Redis Lists (What Sidekiq Uses)
When you do redis.brpop("queue:default"), you’re working with a Redis list:
// Redis list structure (simplified)
typedef struct list {
listNode *head; // First item
listNode *tail; // Last item
long length; // How many items
// ... other fields
} list;
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value; // Your job data
} listNode;
BRPOP implementation inside Redis:
// Simplified BRPOP command handler
void brpopCommand(client *c) {
// Try to pop from each list
for (int i = 1; i < c->argc - 1; i++) {
robj *key = c->argv[i];
robj *list = lookupKeyRead(c->db, key);
if (list && listTypeLength(list) > 0) {
// Found item! Pop and return immediately
robj *value = listTypePop(list, LIST_TAIL);
addReplyMultiBulkLen(c, 2);
addReplyBulk(c, key);
addReplyBulk(c, value);
return;
}
}
// No items found - BLOCK the client
blockForKeys(c, c->argv + 1, c->argc - 2, timeout);
}
🔑 Hash Tables (Super Fast Lookups)
Redis uses hash tables for O(1) key lookups:
// Redis hash table
typedef struct dict {
dictEntry **table; // Array of buckets
unsigned long size; // Size of table
unsigned long sizemask; // size - 1 (for fast modulo)
unsigned long used; // Number of entries
} dict;
// Finding a key
unsigned int hash = dictGenHashFunction(key);
unsigned int idx = hash & dict->sizemask;
dictEntry *entry = dict->table[idx];
This is why Redis is so fast – finding any key is O(1)!
⚡ The Event Loop: Handling Thousands of Connections
Redis uses epoll (Linux) or kqueue (macOS) to efficiently handle many connections:
// Simplified event loop
int epollfd = epoll_create(1024);
// Add client socket to epoll
struct epoll_event ev;
ev.events = EPOLLIN; // Watch for incoming data
ev.data.ptr = client;
epoll_ctl(epollfd, EPOLL_CTL_ADD, client->fd, &ev);
// Main loop
while (1) {
int nfds = epoll_wait(epollfd, events, MAX_EVENTS, timeout);
for (int i = 0; i < nfds; i++) {
client *c = (client*)events[i].data.ptr;
if (events[i].events & EPOLLIN) {
// Data available to read
read_client_command(c);
process_command(c);
}
}
}
Why this is amazing:
Traditional approach: 1 thread per connection
- 1000 connections = 1000 threads
- Each thread uses ~8MB memory
- Context switching overhead
Redis approach: 1 thread for all connections
- 1000 connections = 1 thread
- Minimal memory overhead
- No context switching between connections
🔒 How BRPOP Blocking Actually Works
Here’s the magic behind Sidekiq’s blocking behavior:
🎭 Client Blocking State
// When no data available for BRPOP
typedef struct blockingState {
dict *keys; // Keys we're waiting for
time_t timeout; // When to give up
int numreplicas; // Replication stuff
// ... other fields
} blockingState;
// Block a client
void blockClient(client *c, int btype) {
c->flags |= CLIENT_BLOCKED;
c->btype = btype;
c->bstate = zmalloc(sizeof(blockingState));
// Add to server's list of blocked clients
listAddNodeTail(server.clients, c);
}
// When someone does LPUSH to a list
void signalKeyAsReady(redisDb *db, robj *key) {
readyList *rl = zmalloc(sizeof(*rl));
rl->key = key;
rl->db = db;
// Add to ready list
listAddNodeTail(server.ready_keys, rl);
}
// Process ready keys and unblock clients
void handleClientsBlockedOnKeys(void) {
while (listLength(server.ready_keys) != 0) {
listNode *ln = listFirst(server.ready_keys);
readyList *rl = listNodeValue(ln);
// Find blocked clients waiting for this key
list *clients = dictFetchValue(rl->db->blocking_keys, rl->key);
if (clients) {
// Unblock first client and serve the key
client *receiver = listNodeValue(listFirst(clients));
serveClientBlockedOnList(receiver, rl->key, rl->db);
}
listDelNode(server.ready_keys, ln);
}
}
💾 Memory Management: Keeping It All in RAM
🧮 Memory Layout
// Every Redis object has this header
typedef struct redisObject {
unsigned type:4; // STRING, LIST, SET, etc.
unsigned encoding:4; // How it's stored internally
unsigned lru:24; // LRU eviction info
int refcount; // Reference counting
void *ptr; // Actual data
} robj;
🗂️ Smart Encodings
Redis automatically chooses the most efficient representation:
// Small lists use ziplist (compressed)
if (listLength(list) < server.list_max_ziplist_entries &&
listTotalSize(list) < server.list_max_ziplist_value) {
// Use compressed ziplist
listConvert(list, OBJ_ENCODING_ZIPLIST);
} else {
// Use normal linked list
listConvert(list, OBJ_ENCODING_LINKEDLIST);
}
Client ─→ Hash Key ─→ Determine Slot ─→ Route to Correct Node
Slots 0-5460: Node A
Slots 5461-10922: Node B
Slots 10923-16383: Node C
🔍 Monitoring Redis
# Real-time stats
redis-cli info
# Monitor all commands
redis-cli monitor
# Check slow queries
redis-cli slowlog get 10
# Memory usage by key pattern
redis-cli --bigkeys
🎯 Redis vs Alternatives
📊 When to Choose Redis
✅ Need sub-millisecond latency
✅ Working with simple data structures
✅ Caching frequently accessed data
✅ Session storage
✅ Real-time analytics
✅ Message queues (like Sidekiq!)
❌ Need complex queries (use PostgreSQL)
❌ Need ACID transactions across keys
❌ Dataset larger than available RAM
❌ Need strong consistency guarantees
# Modern alternative to lists for job queues
redis.xadd("jobs", {"type" => "email", "user_id" => 123})
redis.xreadgroup("workers", "worker-1", "jobs", ">")
📡 Redis Modules
RedisJSON: Native JSON support
RedisSearch: Full-text search
RedisGraph: Graph database
RedisAI: Machine learning
TimeSeries: Time-series data
⚡ Custom data structures are optimized for specific use cases
🌐 Event-driven networking handles thousands of connections efficiently
🔒 Blocking operations like BRPOP are elegant and efficient
💾 Smart memory management keeps everything fast and compact
📈 Horizontal scaling is possible with clustering and replication
🌟 Conclusion
Redis is a masterclass in software design – taking a simple concept (in-memory data structures) and optimizing every single aspect to perfection. When Sidekiq calls BRPOP, it’s leveraging decades of systems programming expertise distilled into one of the most elegant and performant pieces of software ever written.
The next time you see Redis handling thousands of operations per second while using minimal resources, you’ll understand the beautiful engineering that makes it possible. From hash tables to event loops to memory management, every component works in harmony to deliver the performance that makes modern applications possible.
Redis proves that sometimes the best solutions are the simplest ones, executed flawlessly! 🚀
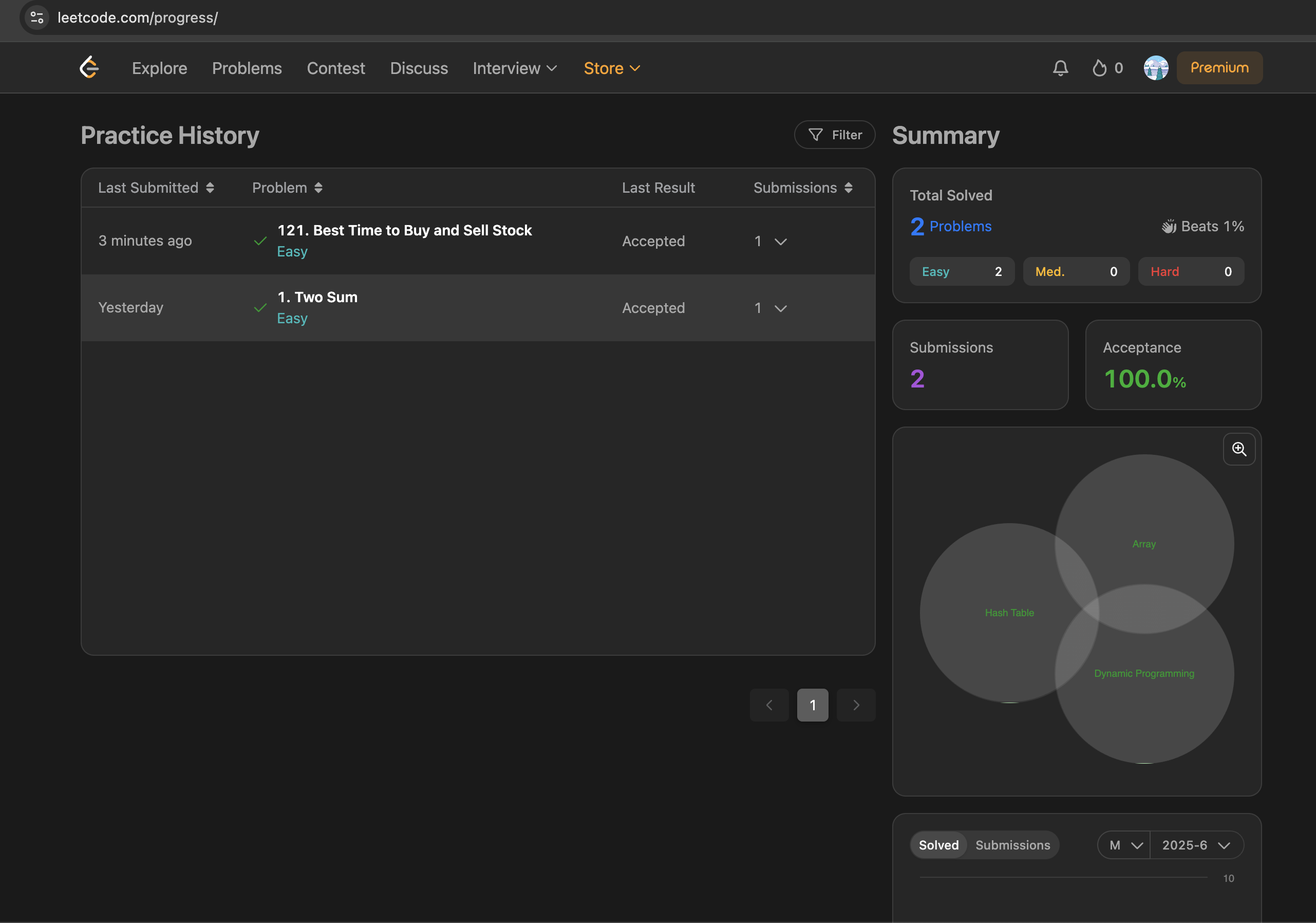
As a Ruby developer working through LeetCode problems, I found myself facing a common challenge: how to ensure all my solutions remain working as I refactor and optimize them? With multiple algorithms per problem and dozens of solution files, manual testing was becoming a bottleneck.
Today, I’ll share how I set up a comprehensive GitHub Actions CI/CD pipeline that automatically tests all my LeetCode solutions, providing instant feedback and maintaining code quality.
🤔 The Problem: Testing Chaos
My LeetCode repository structure looked like this:
Complete Validation: Ensures all solutions work together
Cleaner CI History: Single status check per push/PR
Auto-Discovery: Automatically finds new test folders
❌ Rejected Alternative (Separate Actions):
More complex maintenance
Higher resource usage
Fragmented test results
More configuration overhead
🛠️ The Solution: Intelligent Test Discovery
Here’s the GitHub Actions workflow that changed everything:
name: Run All LeetCode Tests
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Ruby
uses: ruby/setup-ruby@v1
with:
ruby-version: '3.2'
bundler-cache: true
- name: Install dependencies
run: |
gem install minitest
# Add any other gems your tests need
- name: Run all tests
run: |
echo "🧪 Running LeetCode Solution Tests..."
# Colors for output
GREEN='\033[0;32m'
RED='\033[0;31m'
YELLOW='\033[1;33m'
NC='\033[0m' # No Color
# Track results
total_folders=0
passed_folders=0
failed_folders=()
# Find all folders with test files
for folder in */; do
folder_name=${folder%/}
# Skip if no test files in folder
if ! ls "$folder"test_*.rb 1> /dev/null 2>&1; then
continue
fi
total_folders=$((total_folders + 1))
echo -e "\n${YELLOW}📁 Testing folder: $folder_name${NC}"
# Run tests for this folder
cd "$folder"
test_failed=false
for test_file in test_*.rb; do
if [ -f "$test_file" ]; then
echo " 🔍 Running $test_file..."
if ruby "$test_file"; then
echo -e " ${GREEN}✅ $test_file passed${NC}"
else
echo -e " ${RED}❌ $test_file failed${NC}"
test_failed=true
fi
fi
done
if [ "$test_failed" = false ]; then
echo -e "${GREEN}✅ All tests passed in $folder_name${NC}"
passed_folders=$((passed_folders + 1))
else
echo -e "${RED}❌ Some tests failed in $folder_name${NC}"
failed_folders+=("$folder_name")
fi
cd ..
done
# Summary
echo -e "\n🎯 ${YELLOW}TEST SUMMARY${NC}"
echo "📊 Total folders tested: $total_folders"
echo -e "✅ ${GREEN}Passed: $passed_folders${NC}"
echo -e "❌ ${RED}Failed: $((total_folders - passed_folders))${NC}"
if [ ${#failed_folders[@]} -gt 0 ]; then
echo -e "\n${RED}Failed folders:${NC}"
for folder in "${failed_folders[@]}"; do
echo " - $folder"
done
exit 1
else
echo -e "\n${GREEN}🎉 All tests passed successfully!${NC}"
fi
🔍 What Makes This Special?
🎯 Intelligent Auto-Discovery
The script automatically finds folders containing test_*.rb files:
# Skip if no test files in folder
if ! ls "$folder"test_*.rb 1> /dev/null 2>&1; then
continue
fi
This means new problems automatically get tested without workflow modifications!
The status badge is a visual indicator that shows the current status of your GitHub Actions workflow. It’s a small image that displays whether your latest tests are passing or failing.
🎨 What It Looks Like:
✅ When tests pass: ❌ When tests fail: 🔄 When tests are running:
📋 What Information It Shows:
Workflow Name: “Run All LeetCode Tests” (or whatever you named it)
Current Status:
Green ✅: All tests passed
Red ❌: Some tests failed
Yellow 🔄: Tests are currently running
Real-time Updates: Automatically updates when you push code
# Compare solution_v1.rb vs solution_v2.rb performance
💡 Conclusion: Why This Matters
This GitHub Actions setup transformed my LeetCode practice from a manual, error-prone process into a professional, automated workflow. The key benefits:
🎯 For Individual Practice
Confidence: Refactor without fear
Speed: Instant validation of changes
Quality: Consistent test coverage
🎯 For Team Collaboration
Standards: Enforced testing practices
Reviews: Clear CI status on pull requests
Documentation: Professional presentation
🎯 For Career Development
Portfolio: Demonstrates DevOps knowledge
Best Practices: Shows understanding of CI/CD
Professionalism: Industry-standard development workflow
🚀 Take Action
Ready to implement this in your own LeetCode repository? Here’s what to do next:
Copy the workflow file into .github/workflows/test.yml
Ensure consistent naming with test_*.rb pattern
Push to GitHub and watch the magic happen
Add the status badge to your README
Start coding fearlessly with automated testing backup!
How to eliminate API contract mismatches and generate TypeScript clients automatically from your Rails API
🔥 The Problem: API Contract Chaos
If you’ve ever worked on a project with a Rails backend and a TypeScript frontend, you’ve probably experienced this scenario:
Backend developer changes an API response format
Frontend breaks silently in production
Hours of debugging to track down the mismatch
Manual updates to TypeScript types that drift out of sync
Sound familiar? This is the classic API contract problem that plagues full-stack development.
🛡️ Enter Camille: Your API Contract Guardian
Camille is a gem created by Basecamp that solves this problem elegantly by:
Defining API contracts once in Ruby
Generating TypeScript types automatically
Validating responses at runtime to ensure contracts are honored
Creating typed API clients for your frontend
Let’s explore how we implemented Camille in a real Rails API project.
🏗️ Our Implementation: A User Management API
We built a simple Rails API-only application with user management functionality. Here’s how Camille transformed our development workflow:
1️⃣ Defining the Type System
First, we defined our core data types in config/camille/types/user.rb:
using Camille::Syntax
class Camille::Types::User < Camille::Type
include Camille::Types
alias_of(
id: String,
name: String,
biography: String,
created_at: String,
updated_at: String
)
end
This single definition becomes the source of truth for what a User looks like across your entire stack.
2️⃣ Creating API Schemas
Next, we defined our API endpoints in config/camille/schemas/users.rb:
using Camille::Syntax
class Camille::Schemas::Users < Camille::Schema
include Camille::Types
# GET /user - Get a random user
get :show do
response(User)
end
# POST /user - Create a new user
post :create do
params(
name: String,
biography: String
)
response(User | { error: String })
end
end
Notice the union typeUser | { error: String } – Camille supports sophisticated type definitions including unions, making your contracts precise and expressive.
3️⃣ Implementing the Rails Controller
Our controller implementation focuses on returning data that matches the Camille contracts:
class UsersController < ApplicationController
def show
@user = User.random_user
if @user
render json: UserSerializer.serialize(@user), status: :ok
else
render json: { error: "No users found" }, status: :not_found
end
end
def create
@user = User.new(user_params)
return validation_error(@user) unless @user.valid?
return random_failure if simulate_failure?
if @user.save
render json: UserSerializer.serialize(@user), status: :ok
else
validation_error(@user)
end
end
private
def user_params
params.permit(:name, :biography)
end
end
4️⃣ Creating a Camille-Compatible Serializer
The key to making Camille work is ensuring your serializer returns exactly the hash structure defined in your types:
class UserSerializer
# Serializes a user object to match Camille::Types::User format
def self.serialize(user)
{
id: user.id,
name: user.name,
biography: user.biography,
created_at: user.created_at.iso8601,
updated_at: user.updated_at.iso8601
}
end
end
💡 Pro tip: Notice how we convert timestamps to ISO8601 strings to match our String type definition. Camille is strict about types!
5️⃣ Runtime Validation Magic
Here’s where Camille shines. When we return data that doesn’t match our contract, Camille catches it immediately:
# This would throw a Camille::Controller::TypeError
render json: @user # ActiveRecord object doesn't match hash contract
# This works perfectly
render json: UserSerializer.serialize(@user) # Hash matches contract
The error messages are incredibly helpful:
Camille::Controller::TypeError (
Type check failed for response.
Expected hash, got #<User id: "58601411-4f94-4fd2-a852-7a4ecfb96ce2"...>.
)
🎯 Frontend Benefits: Auto-Generated TypeScript
While we focused on the Rails side, Camille’s real power shows on the frontend. It generates TypeScript types like:
// Auto-generated from your Ruby definitions
export interface User {
id: string;
name: string;
biography: string;
created_at: string;
updated_at: string;
}
export type CreateUserResponse = User | { error: string };
🧪 Testing with Camille
We created comprehensive tests to ensure our serializers work correctly:
class UserSerializerTest < ActiveSupport::TestCase
test "serialize returns correct hash structure" do
result = UserSerializer.serialize(@user)
assert_instance_of Hash, result
assert_equal 5, result.keys.length
# Check all required keys match Camille type
assert_includes result.keys, :id
assert_includes result.keys, :name
assert_includes result.keys, :biography
assert_includes result.keys, :created_at
assert_includes result.keys, :updated_at
end
test "serialize returns timestamps as ISO8601 strings" do
result = UserSerializer.serialize(@user)
iso8601_regex = /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(Z|\.\d{3}Z)$/
assert_match iso8601_regex, result[:created_at]
assert_match iso8601_regex, result[:updated_at]
end
end
⚙️ Configuration and Setup
Setting up Camille is straightforward:
Add to Gemfile:
gem "camille"
Configure in config/camille.rb:
Camille.configure do |config|
config.ts_header = <<~EOF
// DO NOT EDIT! This file is automatically generated.
import request from './request'
EOF
end
Generate TypeScript:
rails camille:generate
💎 Best Practices We Learned
🎨 1. Dedicated Serializers
Don’t put serialization logic in models. Create dedicated serializers that focus solely on Camille contract compliance.
🔍 2. Test Your Contracts
Write tests that verify your serializers return the exact structure Camille expects. This catches drift early.
🔀 3. Use Union Types
Leverage Camille’s union types (User | { error: String }) to handle success/error responses elegantly.
⏰ 4. String Timestamps
Convert DateTime objects to ISO8601 strings for consistent frontend handling.
🚶♂️ 5. Start Simple
Begin with basic types and schemas, then evolve as your API grows in complexity.
📊 The Impact: Before vs. After
❌ Before Camille:
❌ Manual TypeScript type definitions
❌ Runtime errors from type mismatches
❌ Documentation drift
❌ Time wasted on contract debugging
✅ After Camille:
✅ Single source of truth for API contracts
✅ Automatic TypeScript generation
✅ Runtime validation catches issues immediately
✅ Self-documenting APIs
✅ Confident deployments
⚡ Performance Considerations
You might worry about runtime validation overhead. In our testing:
Development: Invaluable for catching issues early
Test: Perfect for ensuring contract compliance
Production: Consider disabling for performance-critical apps
# Disable in production if needed
config.camille.validate_responses = !Rails.env.production?
🎯 When to Use Camille
✅ Perfect for:
Rails APIs with TypeScript frontends
Teams wanting strong API contracts
Projects where type safety matters
Microservices needing clear interfaces
🤔 Consider alternatives if:
You’re using GraphQL (already type-safe)
Simple APIs with stable contracts
Performance is absolutely critical
🎉 Conclusion
Camille transforms Rails API development by bringing type safety to the Rails-TypeScript boundary. It eliminates a whole class of bugs while making your API more maintainable and self-documenting.
The initial setup requires some discipline – you need to think about your types upfront and maintain serializers. But the payoff in reduced debugging time and increased confidence is enormous.
For our user management API, Camille caught several type mismatches during development that would have been runtime bugs in production. The auto-generated TypeScript types kept our frontend in perfect sync with the backend.
If you’re building Rails APIs with TypeScript frontends, give Camille a try. Your future self (and your team) will thank you.
Want to see the complete implementation? Check out our example repository with a fully working Rails + Camille setup.
Welcome to my new series where I combine the power of Ruby with the discipline of Test-Driven Development (TDD) to tackle popular algorithm problems from LeetCode! 🧑💻💎 Whether you’re a Ruby enthusiast looking to sharpen your problem-solving skills, or a developer curious about how TDD can transform the way you approach coding challenges, you’re in the right place.
🎲 Episode 2: Best Time to Buy and Sell Stock
###############################################
# Problem 2: Best Time to Buy and Sell Stock
###############################################
You are given an array prices where prices[i] is the price of a given stock on the ith day.
You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
Example 1:
Input: prices = [7,1,5,3,6,4]
Output: 5
Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.
Note that buying on day 2 and selling on day 1 is not allowed because you must buy before you sell.
Example 2:
Input: prices = [7,6,4,3,1]
Output: 0
Explanation: In this case, no transactions are done and the max profit = 0.
Constraints:
1 <= prices.length <= 105
0 <= prices[i] <= 104
# frozen_string_literal: true
# ❌ first failing test case
require 'minitest/autorun'
#####################
##
#####################
class TestBuySell < Minitest::Test
def setup
####
end
# ex: []
def test_array_is_an_empty_array
assert_equal 'Provide an array of two or more elements', []
end
end
########################
# @param {Integer[]} prices
# @return {Integer}
# Ex: max_profit([])
def max_profit
'Provide an array of two or more elements' if @prices.empty?
end
…………………………………………………. ⤵ …………………………………………………………..
Writing the Second Test Case:
# frozen_string_literal: true
# ❌ second failing test case
require 'minitest/autorun'
#####################
##
#####################
class TestBuySell < Minitest::Test
def setup
####
end
# ex: []
def test_array_is_an_empty_array
assert_equal 'Provide an array of two or more elements', []
end
def test_array_with_length_one
assert_equal 'Provide an array of two or more elements', [1]
end
end
########################
# @param {Integer[]} prices
# @return {Integer}
# Ex: BuySellStock.new([2,8]).max_profit
def max_profit
'Provide an array of two or more elements' if @prices.length < 2
end
…………………………………………………. ⤵ …………………………………………………………..
Writing the Third, Fourth Test Case:
# frozen_string_literal: true
require 'minitest/autorun'
require_relative 'buy_sell'
#####################
##
#####################
class TestBuySellStock < Minitest::Test
def setup
####
end
def create_array(length)
Array.new(length) { rand(1..100) }
end
# ex: BuySellStock.new([]).max_profit
def test_array_is_an_empty_array
assert_equal 'Provide an array of two or more elements', BuySellStock.new([]).max_profit
end
def test_array_with_length_one
assert_equal 'Provide an array of two or more elements', BuySellStock.new([1]).max_profit
end
def test_array_with_length_two
assert_equal 2, BuySellStock.new([1, 3]).max_profit
assert_equal 0, BuySellStock.new([5, 3]).max_profit
end
def test_array_with_length_three
assert_equal 5, BuySellStock.new([1, 3, 6]).max_profit
assert_equal 0, BuySellStock.new([5, 3, 2]).max_profit
end
end
Solution 1 ✅
########################
# @param {Integer[]} prices
# @return {Integer}
# Ex: BuySellStock.new([2,8]).max_profit
########################
class BuySellStock
def initialize(prices)
@prices = prices
@profit_store = {}
end
def max_profit
return 'Provide an array of two or more elements' if @prices.length < 2
# iterate today's price
@prices.each_with_index do |todays_price, index|
# check profit with future prices
@prices[(index + 1)..].each do |future_price|
profit = future_price - todays_price
update_profit_store(index, profit) if profit.positive?
end
end
@profit_store.values.max || 0
end
def update_profit_store(index, profit)
@profit_store[index] = 0 unless @profit_store[index]
@profit_store[index] = profit if profit > @profit_store[index]
end
end
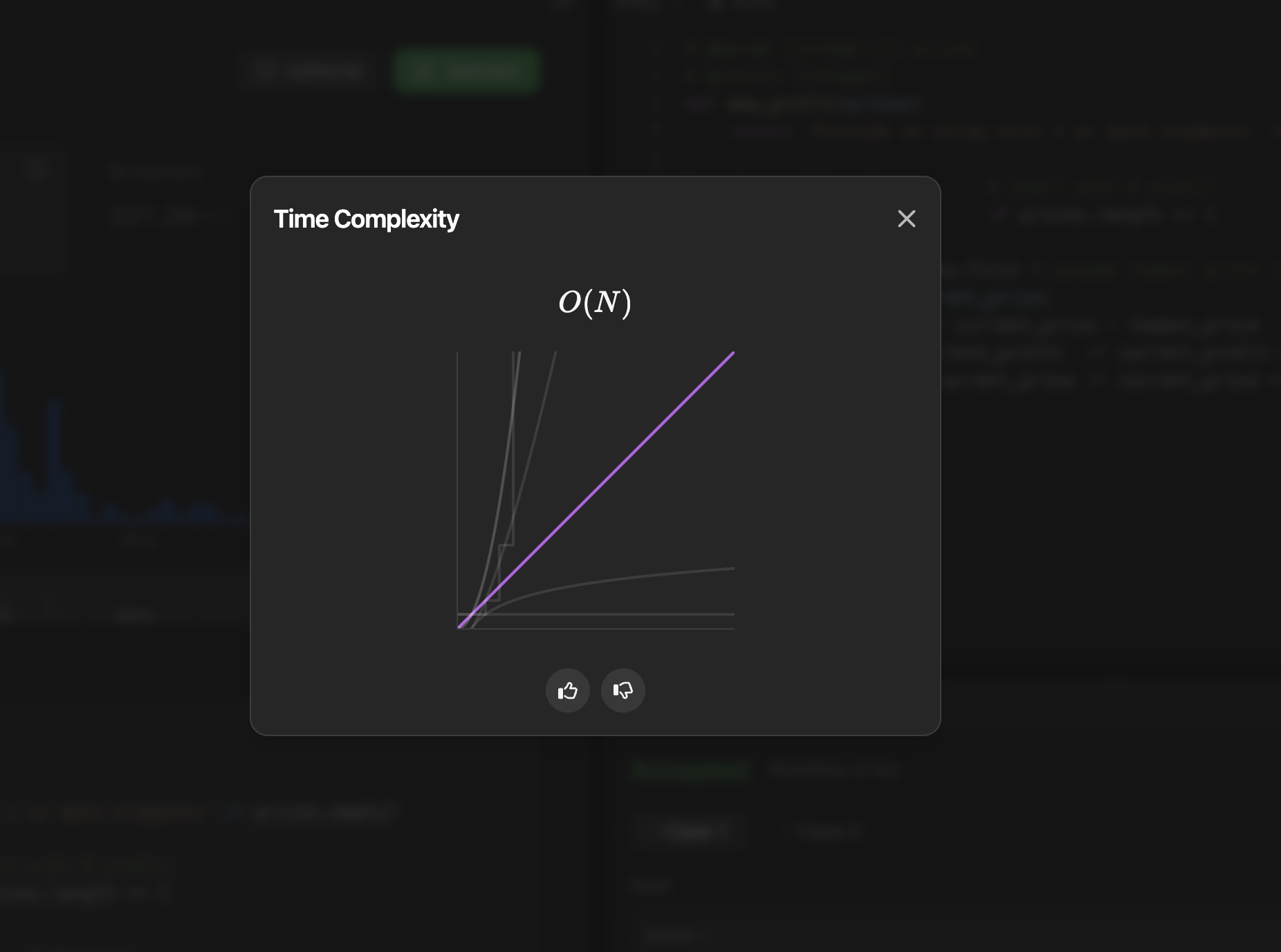
⏳ Finding the Time Complexity
Let me analyze the time complexity of your algorithm in buy_sell.rb.
Looking at our code, there are two nested loops:
The outer loop iterates through each price in the array using each_with_index
The inner loop iterates through all future prices using @prices[(index + 1)..]
For an array of length n:
The outer loop runs n times
For each iteration of the outer loop, the inner loop runs (n-1), (n-2), (n-3), …, 1 times
This creates a pattern of:
First iteration: n-1 comparisons
Second iteration: n-2 comparisons
Third iteration: n-3 comparisons
And so on…
This is equivalent to the sum of the first (n-1) natural numbers: (n-1) + (n-2) + (n-3) + … + 1 = n(n-1)/2
Therefore, the time complexity is O(n²) or quadratic time complexity.
The space complexity is O(n) because:
We store the prices array: O(n)
We store the profit_store hash which in worst case could store n-1 entries: O(n)
💡 Tip: To optimize this, we could use a single pass approach that keeps track of the minimum price seen so far and calculates the maximum profit in one iteration, which would give you O(n)time complexity.
♻️ Refactor: Optimizing the solution
Let’s optimize the algorithm step by step. Modify our code to achieve O(n) time complexity.
The key insight is that we only need to:
Keep track of the minimum price we’ve seen so far
For each price, calculate the potential profit if we sell at current price
Update the maximum profit if current profit is higher
Here’s how we’ll modify your code:
Let me explain the optimization step by step:
First, we remove the @profit_store hash since we don’t need it anymore:
def initialize(prices)
@prices = prices
end
In the max_profit method, we’ll use two variables:
min_price: to keep track of the lowest price we’ve seen so far
max_profit: to keep track of the maximum profit we can make
The optimized algorithm snippet looks like this (Check: Final Solution ✅ at the bottom):
def max_profit
return 'Provide an array of two or more elements' if @prices.length < 2
min_price = @prices[0] # Start with first price as minimum
max_profit = 0 # Start with 0 profit
@prices.each do |price|
# Update min_price if current price is lower
min_price = [min_price, price].min
# Calculate potential profit
potential_profit = price - min_price
# Update max_profit if current profit is higher
max_profit = [max_profit, potential_profit].max
end
max_profit
end
Let’s walk through how this works with the example [7,1,5,3,6,4]:
the optimized algorithm I described above works perfectly for this problem! Let me explain why:
The Problem Requirements:
Choose a single day to buy one stock
Choose a different day in the future to sell that stock
Maximize profit from this transaction
Return 0 if no profit is possible
How the Optimized Algorithm Satisfies These Requirements:
Single buy/sell transaction: ✅ The algorithm finds the best single buy-sell pair
Buy before sell: ✅ As we iterate through the array, min_price always represents a price from a previous day (or current day), ensuring we buy before we sell
Maximize profit: ✅ We keep track of the maximum profit seen so far
Return 0 if no profit: ✅ We initialize max_profit = 0 and only update it if we find a positive profit
Key Insight:
The algorithm works because at any given day, the maximum profit we can achieve by selling on that day is: current_price - minimum_price_seen_so_far
Since we process prices chronologically, the minimum price we’ve seen so far is always from a previous day (or the same day), which satisfies the “buy before sell” constraint.
Start with min_price = 7 and max_profit = 0
Example with [7,1,5,3,6,4]:
Day 0: price=7, min_price=7, profit=0
Day 1: price=1, min_price=1, profit=0
Day 2: price=5, min_price=1, profit=4 (buy day 1, sell day 2)
Day 3: price=3, min_price=1, profit=2 (buy day 1, sell day 3)
Day 4: price=6, min_price=1, profit=5 (buy day 1, sell day 4) ← Maximum
Day 5: price=4, min_price=1, profit=3 (buy day 1, sell day 5)
The algorithm correctly identifies buying on day 1 (price=1) and selling on day 4 (price=6) for maximum profit of 5.
The time complexity is now O(n) because:
We only make a single pass through the array
Each operation inside the loop is O(1)
No nested loops
The space complexity is O(1) because:
We only use two variables regardless of input size
We don’t store any additional data structures
Your Current Algorithm vs Optimized:
Your current O(n²) algorithm: Works correctly but inefficient
Optimized O(n) algorithm: Works correctly and much more efficient
Both solve the same problem correctly, but the optimized version is significantly faster for large inputs.
♻️ Refactor: Try to find a solution below o(n^2) time complexity
# Solution 2 ✅ - Final Solution submitted
# frozen_string_literal: true
##########################################
#
# You are given an array prices where prices[i] is the price of a given stock on the ith day.
# You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
# Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
# Example 1:
# Input: prices = [7,1,5,3,6,4]
# Output: 5
# Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.
# Note that buying on day 2 and selling on day 1 is not allowed because you must buy before you sell.
# Example 2:
# Input: prices = [7,6,4,3,1]
# Output: 0
# Explanation: In this case, no transactions are done and the max profit = 0.
#
# Constraints:
# 1 <= prices.length <= 105
# 0 <= prices[i] <= 104
##########################################
# @param {Integer[]} prices
# @return {Integer}
# Ex: BuySellStock.new([2,8]).max_profit
class BuySellStock
def initialize(prices)
@prices = prices
@profit_store = {}
end
def max_profit
return 'Provide an array with 1 or more elements' if @prices.empty?
max_profit = 0 # Start with 0 profit
return max_profit if @prices.length == 1
lowest_price = @prices.first # assume lowest price is the first price
@prices.each do |current_price|
current_profit = current_price - lowest_price
max_profit = current_profit if current_profit > max_profit
lowest_price = current_price if current_price < lowest_price
end
max_profit
end
end
##########
# Solution 3 ✅ - For Reference by AI
# frozen_string_literal: true
##########################################
#
# You are given an array prices where prices[i] is the price of a given stock on the ith day.
# You want to maximize your profit by choosing a single day to buy one stock and choosing a different day in the future to sell that stock.
# Return the maximum profit you can achieve from this transaction. If you cannot achieve any profit, return 0.
# Example 1:
# Input: prices = [7,1,5,3,6,4]
# Output: 5
# Explanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.
# Note that buying on day 2 and selling on day 1 is not allowed because you must buy before you sell.
# Example 2:
# Input: prices = [7,6,4,3,1]
# Output: 0
# Explanation: In this case, no transactions are done and the max profit = 0.
#
# Constraints:
# 1 <= prices.length <= 105
# 0 <= prices[i] <= 104
##########################################
# @param {Integer[]} prices
# @return {Integer}
# Ex: BuySellStock.new([2,8]).max_profit
class BuySellStock
def initialize(prices)
@prices = prices
@profit_store = {}
end
def max_profit
return 'Provide an array with 1 or more elements' if @prices.empty?
max_profit = 0 # Start with 0 profit
return max_profit if @prices.length == 1
min_price = @prices[0] # Start with first price as minimum
@prices.each do |price|
# Update min_price if current price is lower
min_price = [min_price, price].min
# Calculate potential profit
potential_profit = price - min_price
# Update max_profit if current profit is higher
max_profit = [max_profit, potential_profit].max
end
max_profit
end
end
Time Complexity: O(n) ✅
About the time complexity being O(n). Here’s why:
You have a single loop that iterates through the @prices array once: @prices.each do |current_price|
max_profit = current_profit if current_profit > max_profit → O(1)
lowest_price = current_price if current_price < lowest_price → O(1)
No nested loops, no recursive calls
Total: O(n)
Space Complexity: O(1) – Not O(n)
It’s actually O(1) constant space, not O(n). Here’s why:
Space used:
max_profit variable → O(1)
lowest_price variable → O(1)
current_price (loop variable) → O(1)
current_profit variable → O(1)
The @prices array → This is input data, not additional space used by the algorithm
@profit_store → You’re not using this anymore in the optimized version
Key Point: In space complexity analysis, we typically don’t count the input data itself. We only count the additional space the algorithm uses beyond the input. Since you’re only using a constant number of variables (4 variables) regardless of the input size, the space complexity is O(1).
Welcome to my new series where I combine the power of Ruby with the discipline of Test-Driven Development (TDD) to tackle popular algorithm problems from LeetCode! 🧑💻💎 Whether you’re a Ruby enthusiast looking to sharpen your problem-solving skills, or a developer curious about how TDD can transform the way you approach coding challenges, you’re in the right place. In each episode, I’ll walk through a classic algorithm problem, show how TDD guides my thinking, and share insights I gain along the way. Let’s dive in and discover how writing tests first can make us better, more thoughtful programmers – one problem at a time! 🚀
🎯 Why I chose this approach
When I decided to level up my algorithmic thinking, I could have simply jumped into solving problems and checking solutions afterward. But I chose a different path – Test-Driven Development with Ruby – and here’s why this combination is pure magic ✨. Learning algorithms through TDD forces me to think before I code, breaking down complex problems into small, testable behaviors. Instead of rushing to implement a solution, I first articulate what the function should do in various scenarios through tests.
This approach naturally leads me to discover edge cases I would have completely missed otherwise – like handling empty arrays, negative numbers, or boundary conditions that only surface when you’re forced to think about what could go wrong. Ruby’s expressive syntax makes writing these tests feel almost conversational, while the red-green-refactor cycle ensures I’m not just solving the problem, but solving it elegantly. Every failing test becomes a mini-puzzle to solve, every passing test builds confidence, and every refactor teaches me something new about both the problem domain and Ruby itself. It’s not just about getting the right answer – it’s about building a robust mental model of the problem while writing maintainable, well-tested code. 🚀
🎲 Episode 1: The Two Sum Problem
#####################################
# Problem 1: The Two Sum Problem
#####################################
# Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target.
# You may assume that each input would have exactly one solution, and you may not use the same element twice.
# You can return the answer in any order.
# Example 1:
# Input: nums = [2,7,11,15], target = 9
# Output: [0,1]
# Explanation: Because nums[0] + nums[1] == 9, we return [0, 1].
# Example 2:
# Input: nums = [3,2,4], target = 6
# Output: [1,2]
# Example 3:
# Input: nums = [3,3], target = 6
# Output: [0,1]
# Constraints:
# Only one valid answer exists.
# We are not considering following concepts for now:
# 2 <= nums.length <= 104
# -109 <= nums[i] <= 109
# -109 <= target <= 109
# Follow-up: Can you come up with an algorithm that is less than O(n2) time complexity?
🔧 Setting up the TDD environment
Create a test file first and add the first test case.
# frozen_string_literal: true
require 'minitest/autorun'
require_relative 'two_sum'
###############################
# This is the test case for finding the index of two numbers in an array
# such that adding both numbers should be equal to the target number provided
#
# Ex:
# two_sum(num, target)
# num: [23, 4, 8, 92], tatget: 12
# output: [1, 2] => index of the two numbers whose sum is equal to target
##############################
class TestTwoSum < Minitest::Test
def setup
####
end
def test_array_is_an_empty_array
assert_equal 'Provide an array with length 2 or more', two_sum([], 9)
end
end
Create the problem file: two_sum.rb with empty method first.
ruby test_two_sum.rb
Run options: --seed 58910
# Running:
F
Finished in 0.008429s, 118.6380 runs/s, 118.6380 assertions/s.
1) Failure:
TestTwoSum#test_array_is_an_empty_array [test_two_sum.rb:21]:
--- expected
+++ actual
@@ -1 +1 @@
-"Provide an array with length 2 or more"
+nil
1 runs, 1 assertions, 1 failures, 0 errors, 0 skips
✅ Green: Making it pass
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
def two_sum(nums, target)
'Provide an array with length 2 or more' if nums.empty?
end
♻️ Refactor: Optimizing the solution
❌
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
def two_sum(nums, target)
return 'Provide an array with length 2 or more' if nums.empty?
nums.each_with_index do |selected_num, selected_index|
nums.each_with_index do |num, index|
if selected_index != index
sum = selected_num[selected_index] + num[index]
return [selected_index, index] if sum == target
end
end
end
end
❌
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
def two_sum(nums, target)
return 'Provide an array with length 2 or more' if nums.empty?
nums.each_with_index do |selected_num, selected_index|
nums.each_with_index do |num, index|
next if selected_index == index
sum = selected_num[selected_index] + num[index]
return [selected_index, index] if sum == target
end
end
end
✅
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
def two_sum(nums, target)
return 'Provide an array with length 2 or more' if nums.empty?
nums.each_with_index do |selected_num, selected_index|
nums.each_with_index do |num, index|
next if index <= selected_index
return [selected_index, index] if selected_num + num == target
end
end
end
Final
# frozen_string_literal: true
require 'minitest/autorun'
require_relative 'two_sum'
###############################
# This is the test case for finding the index of two numbers in an array
# such that adding both numbers should be equal to the target number provided
#
# Ex:
# two_sum(num, target)
# num: [23, 4, 8, 92], tatget: 12
# output: [1, 2] => index of the two numbers whose sum is equal to target
##############################
class TestTwoSum < Minitest::Test
def setup
####
end
def test_array_is_an_empty_array
assert_equal 'Provide an array with length 2 or more elements', two_sum([], 9)
end
def test_array_with_length_one
assert_equal 'Provide an array with length 2 or more elements', two_sum([9], 9)
end
def test_array_with_length_two
assert_equal [0, 1], two_sum([9, 3], 12)
end
def test_array_with_length_three
assert_equal [1, 2], two_sum([9, 3, 4], 7)
end
def test_array_with_length_four
assert_equal [1, 3], two_sum([9, 3, 4, 8], 11)
end
def test_array_with_length_ten
assert_equal [7, 8], two_sum([9, 3, 9, 8, 23, 20, 19, 5, 30, 14], 35)
end
end
# Solution 1 ✅
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
def two_sum(nums, target)
return 'Provide an array with length 2 or more elements' if nums.length < 2
nums.each_with_index do |selected_num, selected_index|
nums.each_with_index do |num, index|
already_added = index <= selected_index
next if already_added
return [selected_index, index] if selected_num + num == target
end
end
end
Let us analyze the time complexity of Solution 1 ✅ algorithm: Our current algorithm is not less than O(n^2) time complexity. In fact, it is exactly O(n^2). This means for an array of length n, you are potentially checking about n(n−1)/2 pairs, which is O(n^2).
🔍 Why?
You have two nested loops:
The outer loop iterates over each element (nums.each_with_index)
The inner loop iterates over each element after the current one (nums.each_with_index)
For each pair, you check if their sum equals the target.
♻️ Refactor: Try to find a solution below n(^2) time complexity
# Solution 2 ✅
#####################################
# Solution 2
# TwoSum.new([2,7,11,15], 9).indices
#####################################
class TwoSum
def initialize(nums, target)
@numbers_array = nums
@target = target
end
# @return [index_1, index_2]
def indices
return 'Provide an array with length 2 or more elements' if @numbers_array.length < 2
@numbers_array.each_with_index do |num1, index1|
next if num1 > @target # number already greater than target
remaining_array = @numbers_array[index1..(@numbers_array.length - 1)]
num2 = find_number(@target - num1, remaining_array)
return [index1, @numbers_array.index(num2)] if num2
end
end
private
def find_number(number, array)
array.each do |num|
return num if num == number
end
nil
end
end
Let us analyze the time complexity of Solution 2 ✅ algorithm:
In the indices method:
We have an outer loop that iterates through @numbers_array (O(n))
For each iteration: => Creating a new array slice remaining_array (O(n) operation) => Calling find_number which is O(n) as it iterates through the remaining array => Using @numbers_array.index(num2) which is another O(n) operation
So the total complexity is:
O(n) for the outer loop
For each iteration:
O(n) for array slicing
O(n) for find_number
O(n) for index lookup
This gives us:
O(n * (n + n + n)) = O(n * 3n) = O(3n²) = O(n²)
The main bottlenecks are:
Creating a new array slice in each iteration
Using index method to find the second number’s position
Linear search in find_number
Solution 3 ✅
To make this truly O(n), we should:
# Use a hash map to store numbers and their indices
# Solution 3 ✅ - Use Hash Map
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
class TwoSum
def initialize(nums, target)
@numbers_array = nums
@target = target
end
# @return [index_1, index_2]
def indices
return 'Provide an array with length 2 or more elements' if @numbers_array.length < 2
hash = {}
@numbers_array.each_with_index do |num, index|
complement = @target - num
# store first number to hash
if index == 0
hash[num] = index
else
# if not first number check store has
return [hash[complement], index] if hash.key?(complement)
# if not found store the num
hash[num] = index
end
end
end
end
Let us analyze the complexity of the current code:
def indices
return 'Provide an array with length 2 or more elements' if @numbers_array.length < 2
hash = {}
@numbers_array.each_with_index do |num, index|
complement = @target - num
# store first number to hash
if index == 0
hash[num] = index
else
# if not first number check store has
if hash.key?(complement)
return [hash[complement], index]
else
# if not found store the num
hash[num] = index
end
end
end
end
The complexity is O(n) because:
Single pass through the array: O(n)
For each iteration:
Hash lookup (hash.key?(complement)): O(1)
Hash insertion (hash[num] = index): O(1)
Basic arithmetic (@target - num): O(1)
Total complexity = O(n) * O(1) = O(n)
The code is still efficient because:
We only traverse the array once
All operations inside the loop are constant time
We don’t have any nested loops or array slicing
Hash operations (lookup and insertion) are O(1)
♻️ Refactor Solution 3 ✅
This is still O(n):
Use a hash map to store numbers and their indices
Avoid array slicing
Avoid using index method
Make a single pass through the array
# ♻️ Refactor Solution 3 ✅ - Use Hash Map
# frozen_string_literal: true
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
class TwoSum
def initialize(nums, target)
@numbers_array = nums
@target = target
end
# @return [index_1, index_2]
def indices
return 'Provide an array with length 2 or more elements' if @numbers_array.length < 2
hash = {}
@numbers_array.each_with_index do |num, index|
complement = @target - num
return [hash[complement], index] if hash.key?(complement)
hash[num] = index
end
end
end
This refactored solution has O(n) time complexity because:
Single pass through the array: O(n)
Hash operations (insertion and lookup) are O(1)
No array slicing or linear searches
Total complexity is O(n)
The algorithm works by:
For each number, calculate its complement (target – current_number)
Check if the complement exists in our hash
If found, return both indices
If not found, store the current number and its index in the hash
The key differences:
Instead of searching for complements in the remaining array, we store numbers we’ve seen in a hash
When we see a new number, we check if its complement exists in our hash
If found, we return both indices
If not found, we store the current number and its index
Detailed explanation of refactored solution 3
I’ll explain how the hash map solution works step by step using the example:
# Input Sample
TwoSum.new([2,7,11,15], 9)
Initial State:
hash = {} # Empty hash map
target = 9
First Iteration (num = 2, index = 0):
complement = 9 - 2 = 7
hash = {} # Empty, so complement 7 not found
hash[2] = 0 # Store 2 with its index 0
@numbers_array.each_with_index do |num, index|
complement = @target - num # Calculate what number we need
if hash.key?(complement) # Check if we've seen the number we need
return [hash[complement], index] # If found, return both indices
end
hash[num] = index # If not found, store current number and its index
end
Key points:
We only need to store each number once in the hash
The hash stores numbers as keys and their indices as values
We check for complements before storing the current number
We only need one pass through the array
This is efficient because:
Hash lookups are O(1)
We only traverse the array once
We don’t need to search through the array multiple times
We don’t need to create array slices
Why the index order has complement index first?
The order of indices in the return statement [hash[complement], index] is important because:
hash[complement] gives us the index of the first number we found (the complement)
index gives us the current position (the second number)
We return them in this order because:
The complement was stored in the hash earlier in the array
The current number is found later in the array
This maintains the order of appearance in the original array
For example, with [2,7,11,15] and target 9:
When we see 7 at index 1:
We look for complement 2 (9-7)
2 was stored at index 0
So we return [0, 1] (indices of [2,7])
If we returned [index, hash[complement]], we would get [1, 0] instead, which would be the reverse order. While the problem allows returning the answer in any order, returning them in the order they appear in the array is more intuitive and matches the example outputs in the problem description.
✅ Solution 4
# Solution 4 ✅ - Use Hash Map
# @param {Integer[]} nums
# @param {Integer} target
# @return {Integer[]}
def two_sum(nums, target)
return 'Provide an array with length 2 or more elements' if nums.length < 2
# number index store, use hash map, store first number in store
store = { nums[0] => 0}
# check the pair from second element
nums.each_with_index do |num, index|
next if index == 0 # already stored first
pair = target - num
return [store[pair], index] if store[pair]
store[num] = index
end
end
Implementing Secure Rails APIs Safeguarding your API isn’t a one-and-done task—it’s a layered approach combining transport encryption, robust authentication, granular authorization, data hygiene, and more. In this post, we’ll walk through twelve core pillars of API security in Rails 8, with code examples and practical tips.
⚙️ 1. Enforce HTTPS Everywhere
Why it matters
Unencrypted HTTP traffic can be intercepted or tampered with. HTTPS (TLS/SSL) ensures end-to-end confidentiality and integrity.
Rails setup
In config/environments/production.rb:
# Forces all access to the app over SSL, uses Strict-Transport-Security, and uses secure cookies.
config.force_ssl = true
This automatically:
Redirects any HTTP request to HTTPS
Sets the Strict-Transport-Security header
Flags cookies as secure
Tip: For development, you can use mkcert or rails dev:ssl to spin up a self-signed certificate.
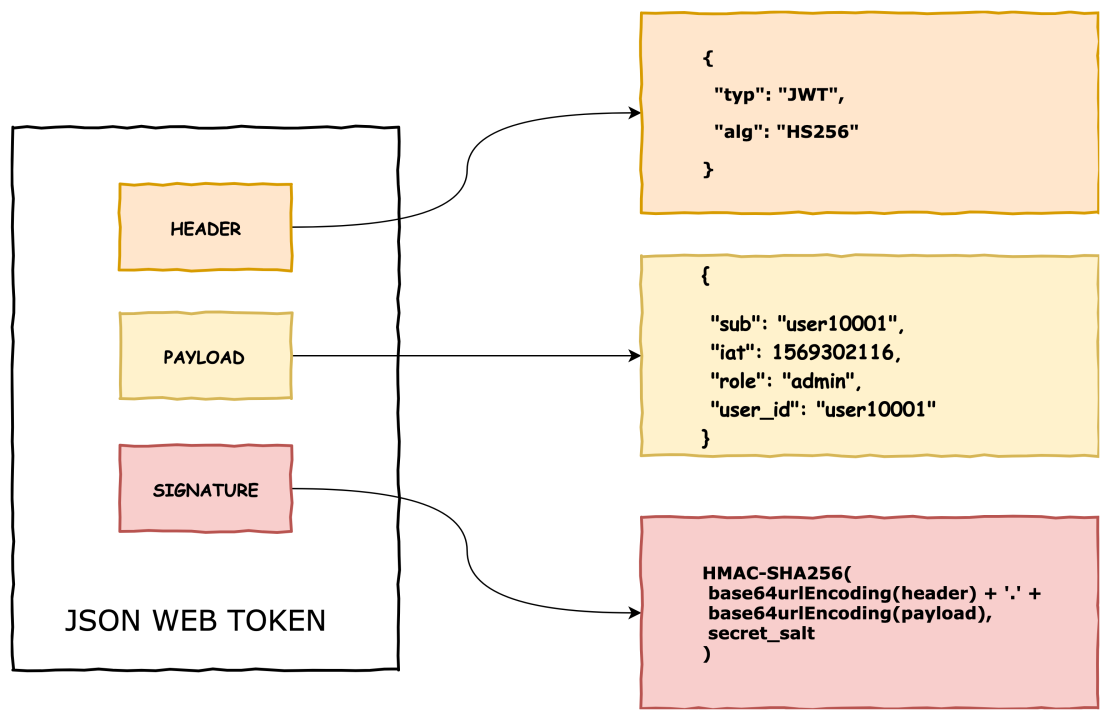
Generating a Token# app/lib/json_web_token.rb module JsonWebToken SECRET = Rails.application.secret_key_base def self.encode(payload, exp = 24.hours.from_now) payload[:exp] = exp.to_i JWT.encode(payload, SECRET) end end
Decoding & Verificationdef self.decode(token) body = JWT.decode(token, SECRET)[0] HashWithIndifferentAccess.new body rescue JWT::ExpiredSignature, JWT::DecodeError nil end
Tip: Always set a reasonable expiration (exp) and consider rotating your secret_key_base periodically.
🛡️ 3. Authorization with Pundit (or CanCanCan)
Why you need it
Authentication only proves identity; authorization controls what that identity can do. Pundit gives you policy classes that cleanly encapsulate permissions.
Example Pundit Setup
Installbundle add pundit
Include# app/controllers/application_controller.rb include Pundit rescue_from Pundit::NotAuthorizedError, with: :permission_denied def permission_denied render json: { error: 'Forbidden' }, status: :forbidden end
Define a Policy# app/policies/post_policy.rb class PostPolicy < ApplicationPolicy def update? user.admin? || record.user_id == user.id end end
Use in Controllerdef update post = Post.find(params[:id]) authorize post # raises if unauthorized post.update!(post_params) render json: post end
Pro Tip: Keep your policy logic simple. If you see repeated conditional combinations, extract them to helper methods or scopes.
🔐 4. Strong Parameters for Mass-Assignment Safety
The risk
Allowing unchecked request parameters can enable attackers to set fields like admin: true.
Best Practice
def user_params
params.require(:user).permit(:name, :email, :password)
end
Require ensures the key exists.
Permit whitelists only safe attributes.
Note: For deeply-nested or polymorphic data, consider using form objects or contracts (e.g., Reform, dry-validation).
⚠️ 5. Rate Limiting with Rack::Attack
Throttling to the rescue
Protects against brute-force, scraping, and DDoS-style abuse.
Setup Example
# Gemfile
gem 'rack-attack'
# config/initializers/rack_attack.rb
class Rack::Attack
# Throttle all requests by IP (60rpm)
throttle('req/ip', limit: 60, period: 1.minute) do |req|
req.ip
end
# Blocklist abusive IPs
blocklist('block 1.2.3.4') do |req|
req.ip == '1.2.3.4'
end
self.cache.store = ActiveSupport::Cache::MemoryStore.new
end
Tip: Customize by endpoint, user, or even specific header values.
🚨 6. Graceful Error Handling & Logging
Leak no secrets
Catching exceptions ensures you don’t reveal stack traces or sensitive internals.
Bundler Audit: checks for known vulnerable gem versions.
Example RSpec test
require 'rails_helper'
RSpec.describe 'Posts API', type: :request do
it 'rejects unauthenticated access' do
get '/api/posts'
expect(response).to have_http_status(:unauthorized)
end
end
CI Tip: Fail your build if Brakeman warnings exceed zero, or if bundle audit finds CVEs.
🪵 12. Log Responsibly
Don’t log sensitive data (passwords, tokens, etc.)
By combining transport security (HTTPS), stateless authentication (JWT), policy-driven authorization (Pundit), parameter safety, rate limiting, controlled data rendering, hardened headers, and continuous testing, you build a defense-in-depth Rails API. Each layer reduces the attack surface—together, they help ensure your application remains robust against evolving threats.
Modern web and mobile applications demand secure APIs. Traditional session-based authentication falls short in stateless architectures like RESTful APIs. This is where Token-Based Authentication and JWT (JSON Web Token) shine. In this blog post, we’ll explore both approaches, understand how they work, and integrate them into a Rails 8 application.
🔐 1. What is Token-Based Authentication?
Token-based authentication is a stateless security mechanism where the server issues a unique, time-bound token after validating a user’s credentials. The client stores this token (usually in local storage or memory) and sends it along with each API request via HTTP headers.
✅ Key Concepts:
Stateless: No session is stored on the server.
Scalable: Ideal for distributed systems.
Tokens can be opaque (random strings).
Algorithms used:
Token generation commonly uses SecureRandom.
🔎 What is SecureRandom?
SecureRandom is a Ruby module that generates cryptographically secure random numbers and strings. It uses operating system facilities (like /dev/urandom on Unix or CryptGenRandom on Windows) to generate high-entropy values that are safe for use in security-sensitive contexts like tokens, session identifiers, and passwords.
For example:
SecureRandom.hex(32) # generates a 64-character hex string (256 bits)
In Ruby, if you encounter the error:
(irb):5:in '<main>': uninitialized constant SecureRandom (NameError)
Did you mean? SecurityError
It means the SecureRandom module hasn’t been loaded. Although SecureRandom is part of the Ruby Standard Library, it’s not automatically loaded in every environment. You need to explicitly require it.
✅ Solution
Add the following line before using SecureRandom:
require 'securerandom'
Then you can use:
SecureRandom.hex(16) # => "a1b2c3d4e5f6..."
📚 Why This Happens
Ruby does not auto-load all standard libraries to save memory and load time. Modules like SecureRandom, CSV, OpenURI, etc., must be explicitly required if you’re working outside of Rails (like in plain Ruby scripts or IRB).
In a Rails environment, require 'securerandom' is typically handled automatically by the framework.
🛠️ Tip for IRB
If you’re experimenting in IRB (interactive Ruby shell), just run:
require 'securerandom'
SecureRandom.uuid # or any other method
This will eliminate the NameError.
🔒 Why 256 bits?
A 256-bit token offers a massive keyspace of 2^256 combinations, making brute-force attacks virtually impossible. The higher the bit-length, the better the resistance to collision and guessing attacks. Most secure tokens range between 128 and 256 bits. While larger tokens are more secure, they consume more memory and storage.
⚠️ Drawbacks:
SecureRandom tokens are opaque and must be stored on the server (e.g., in a database) for validation.
Token revocation requires server-side tracking.
👷️ Implementing Token-Based Authentication in Rails 8
Step 1: Generate User Model
rails g model User email:string password_digest:string token:string
rails db:migrate
JWT is an open standard for secure information exchange, defined in RFC 7519.
🔗 What is RFC 7519?
RFC 7519 is a specification by the IETF (Internet Engineering Task Force) that defines the structure and rules of JSON Web Tokens. It lays out how to encode claims in a compact, URL-safe format and secure them using cryptographic algorithms. It standardizes the way information is passed between parties as a JSON object.
data = "#{base64_header}.#{base64_payload}"
# => "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsImV4cCI6MTcxNzcwMDAwMH0"
🔹 Step 3: Generate Signature using HMAC SHA-256
require 'openssl'
require 'base64'
signature = OpenSSL::HMAC.digest('sha256', secret, data)
# => binary format
encoded_signature = Base64.urlsafe_encode64(signature).gsub('=', '')
# => This is the third part of JWT
# => e.g., "NLoeHhY5jzUgKJGKJq-rK6DTHCKnB7JkPbY3WptZmO8"
✅ Final JWT:
<header>.<payload>.<signature>
Anyone receiving this token can:
Recompute the signature using the same secret key
If it matches the one in the token, it’s valid
If it doesn’t match, the token has been tampered
❓ Is SHA-256 used for encoding or encrypting?
❌ SHA-256 is not encryption. ❌ SHA-256 is not encoding either. ✅ It is a hash function: one-way and irreversible.
It’s used in HMAC to sign data (prove data integrity), not to encrypt or hide data.
✅ Summary:
Purpose
SHA-256 / HMAC SHA-256
Encrypts data?
❌ No
Hides data?
❌ No (use JWE for that)
Reversible?
❌ No
Used in JWT?
✅ Yes (for signature)
Safe?
✅ Very secure if secret is strong
🎯 First: The Big Misunderstanding — Why JWT Isn’t “Encrypted”
JWT is not encrypted by default.
It is just encoded + signed. You can decode the payload, but you cannot forge the signature.
🧠 Difference Between Encoding, Encryption, and Hashing
Concept
Purpose
Reversible?
Example
Encoding
Make data safe for transmission
✅ Yes
Base64
Encryption
Hide data from unauthorized eyes
✅ Yes (with key)
AES, RSA
Hashing
Verify data hasn’t changed
❌ No
SHA-256, bcrypt
🔓 Why can JWT payload be decoded?
Because the payload is only Base64Url encoded, not encrypted.
Example:
{
"user_id": 123,
"role": "admin"
}
When sent in JWT, it becomes:
eyJ1c2VyX2lkIjoxMjMsInJvbGUiOiJhZG1pbiJ9
✅ You can decode it with any online decoder. It’s not private, only structured and verifiable.
🔐 Then What Protects the JWT?
The signature is what protects it.
It proves the payload hasn’t been modified.
The backend signs it with a secret key (HMAC SHA-256 or RS256).
If anyone tampers with the payload and doesn’t have the key, they can’t generate a valid signature.
🧾 Why include the payload inside the JWT?
This is the brilliant part of JWT:
The token is self-contained.
You don’t need a database lookup on every request.
You can extract data like user_id, role, permissions right from the token!
✅ So yes — it’s just a token, but a smart token with claims (data) you can trust.
This is ideal for stateless APIs.
💡 Then why not send payload in POST body?
You absolutely can — and often do, for data-changing operations (like submitting forms). But that’s request data, not authentication info.
JWT serves as the proof of identity and permission, like an ID card.
You put it in the Authorization header, not the body.
📦 Is it okay to send large payloads in JWT?
Technically, yes, but not recommended. Why?
JWTs are sent in every request header — that adds bloat.
Bigger tokens = slower transmission + possible header size limits.
If your payload is very large, use a token to reference it in DB or cache, not store everything in the token.
⚠️ If the secret doesn’t match?
Yes — that means someone altered the token (probably the payload).
If user_id was changed to 999, but they can’t recreate a valid signature (they don’t have the secret), the backend rejects the token.
🔐 Then When Should We Encrypt?
JWT only signs, but not encrypts.
If you want to hide the payload:
Use JWE (JSON Web Encryption) — a different standard.
Or: don’t put sensitive data in JWT at all.
🔁 Summary: Why JWT is a Big Deal
✅ Self-contained authentication
✅ Stateless (no DB lookups)
✅ Signed — so payload can’t be tampered
❌ Not encrypted — anyone can see payload
⚠️ Keep payload small and non-sensitive
🧠 One Last Time: Summary Table
Topic
JWT
POST Body
Used for
Authentication/identity
Submitting request data
Data type
Claims (user_id, role)
Form/input data
Seen by user?
Yes (Base64-encoded)
Yes
Security
Signature w/ secret
HTTPS
Stored where?
Usually in browser (e.g. localStorage, cookie)
N/A
Think of JWT like a sealed letter:
Anyone can read the letter (payload).
But they can’t forge the signature/stamp.
The receiver checks the signature to verify the letter is real and unmodified.
🧨 Yes, JWT Payload is Visible — and That Has Implications
The payload of a JWT is only Base64Url encoded, not encrypted.
This means anyone who has the token (e.g., a user, a man-in-the-middle without HTTPS, or a frontend dev inspecting in the browser) can decode it and see:
It doesn’t prevent others from reading the payload, but it prevents them from modifying it (thanks to the signature).
It allows stateless auth without needing a DB lookup on every request.
It’s useful for microservices where services can verify tokens without a central auth store.
🧰 Best Practices for JWT Payloads
Treat the payload as public data.
Ask yourself: “Is it okay if the user sees this?”
Never trust the token blindly on the client.
Always verify the signature and claims server-side.
Use only identifiers, not sensitive context.
For example, instead of embedding full permissions: { "user_id": 123, "role": "admin" } fetch detailed permissions on the backend based on role.
Encrypt the token if sensitive data is needed.
Use JWE (JSON Web Encryption), or
Store sensitive data on the server and pass only a reference (like a session id or user_id).
📌 Bottom Line
JWT is not private. It is only protected from tampering, not from reading.
So if you use it in your app, make sure the payload contains only safe, public information, and that any sensitive logic (like permission checks) happens on the server.
# app/services/json_web_token.rb
class JsonWebToken
def self.encode(payload, exp = 24.hours.from_now)
payload[:exp] = exp.to_i
JWT.encode(payload, JWT_SECRET, 'HS256')
end
def self.decode(token)
body = JWT.decode(token, JWT_SECRET, true, { algorithm: 'HS256' })[0]
HashWithIndifferentAccess.new body
rescue
nil
end
end
Step 4: Sessions Controller for JWT
# app/controllers/api/v1/sessions_controller.rb
class Api::V1::SessionsController < ApplicationController
def create
user = User.find_by(email: params[:email])
if user&.authenticate(params[:password])
token = JsonWebToken.encode(user_id: user.id)
render json: { jwt: token }, status: :ok
else
render json: { error: 'Invalid credentials' }, status: :unauthorized
end
end
end
Step 5: Authentication in Application Controller
# app/controllers/application_controller.rb
class ApplicationController < ActionController::API
before_action :authenticate_request
def authenticate_request
header = request.headers['Authorization']
token = header.split(' ').last if header
decoded = JsonWebToken.decode(token)
@current_user = User.find_by(id: decoded[:user_id]) if decoded
render json: { error: 'Unauthorized' }, status: :unauthorized unless @current_user
end
end
🌍 How Token-Based Authentication Secures APIs
🔒 Benefits:
Stateless: Scales well
Works across domains
Easy to integrate with mobile/web clients
JWT is tamper-proof and verifiable
⚡ Drawbacks:
Token revocation is hard without server tracking (esp. JWT)
Long-lived tokens can be risky if leaked
Requires HTTPS always
📆 Final Thoughts
For most Rails API-only apps, JWT is the go-to solution due to its stateless, self-contained nature. However, for simpler setups or internal tools, basic token-based methods can still suffice. Choose based on your app’s scale, complexity, and security needs.