How to eliminate API contract mismatches and generate TypeScript clients automatically from your Rails API
🔥 The Problem: API Contract Chaos
If you’ve ever worked on a project with a Rails backend and a TypeScript frontend, you’ve probably experienced this scenario:
Backend developer changes an API response format
Frontend breaks silently in production
Hours of debugging to track down the mismatch
Manual updates to TypeScript types that drift out of sync
Sound familiar? This is the classic API contract problem that plagues full-stack development.
🛡️ Enter Camille: Your API Contract Guardian
Camille is a gem created by Basecamp that solves this problem elegantly by:
Defining API contracts once in Ruby
Generating TypeScript types automatically
Validating responses at runtime to ensure contracts are honored
Creating typed API clients for your frontend
Let’s explore how we implemented Camille in a real Rails API project.
🏗️ Our Implementation: A User Management API
We built a simple Rails API-only application with user management functionality. Here’s how Camille transformed our development workflow:
1️⃣ Defining the Type System
First, we defined our core data types in config/camille/types/user.rb:
using Camille::Syntax
class Camille::Types::User < Camille::Type
include Camille::Types
alias_of(
id: String,
name: String,
biography: String,
created_at: String,
updated_at: String
)
end
This single definition becomes the source of truth for what a User looks like across your entire stack.
2️⃣ Creating API Schemas
Next, we defined our API endpoints in config/camille/schemas/users.rb:
using Camille::Syntax
class Camille::Schemas::Users < Camille::Schema
include Camille::Types
# GET /user - Get a random user
get :show do
response(User)
end
# POST /user - Create a new user
post :create do
params(
name: String,
biography: String
)
response(User | { error: String })
end
end
Notice the union typeUser | { error: String } – Camille supports sophisticated type definitions including unions, making your contracts precise and expressive.
3️⃣ Implementing the Rails Controller
Our controller implementation focuses on returning data that matches the Camille contracts:
class UsersController < ApplicationController
def show
@user = User.random_user
if @user
render json: UserSerializer.serialize(@user), status: :ok
else
render json: { error: "No users found" }, status: :not_found
end
end
def create
@user = User.new(user_params)
return validation_error(@user) unless @user.valid?
return random_failure if simulate_failure?
if @user.save
render json: UserSerializer.serialize(@user), status: :ok
else
validation_error(@user)
end
end
private
def user_params
params.permit(:name, :biography)
end
end
4️⃣ Creating a Camille-Compatible Serializer
The key to making Camille work is ensuring your serializer returns exactly the hash structure defined in your types:
class UserSerializer
# Serializes a user object to match Camille::Types::User format
def self.serialize(user)
{
id: user.id,
name: user.name,
biography: user.biography,
created_at: user.created_at.iso8601,
updated_at: user.updated_at.iso8601
}
end
end
💡 Pro tip: Notice how we convert timestamps to ISO8601 strings to match our String type definition. Camille is strict about types!
5️⃣ Runtime Validation Magic
Here’s where Camille shines. When we return data that doesn’t match our contract, Camille catches it immediately:
# This would throw a Camille::Controller::TypeError
render json: @user # ActiveRecord object doesn't match hash contract
# This works perfectly
render json: UserSerializer.serialize(@user) # Hash matches contract
The error messages are incredibly helpful:
Camille::Controller::TypeError (
Type check failed for response.
Expected hash, got #<User id: "58601411-4f94-4fd2-a852-7a4ecfb96ce2"...>.
)
🎯 Frontend Benefits: Auto-Generated TypeScript
While we focused on the Rails side, Camille’s real power shows on the frontend. It generates TypeScript types like:
// Auto-generated from your Ruby definitions
export interface User {
id: string;
name: string;
biography: string;
created_at: string;
updated_at: string;
}
export type CreateUserResponse = User | { error: string };
🧪 Testing with Camille
We created comprehensive tests to ensure our serializers work correctly:
class UserSerializerTest < ActiveSupport::TestCase
test "serialize returns correct hash structure" do
result = UserSerializer.serialize(@user)
assert_instance_of Hash, result
assert_equal 5, result.keys.length
# Check all required keys match Camille type
assert_includes result.keys, :id
assert_includes result.keys, :name
assert_includes result.keys, :biography
assert_includes result.keys, :created_at
assert_includes result.keys, :updated_at
end
test "serialize returns timestamps as ISO8601 strings" do
result = UserSerializer.serialize(@user)
iso8601_regex = /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(Z|\.\d{3}Z)$/
assert_match iso8601_regex, result[:created_at]
assert_match iso8601_regex, result[:updated_at]
end
end
⚙️ Configuration and Setup
Setting up Camille is straightforward:
Add to Gemfile:
gem "camille"
Configure in config/camille.rb:
Camille.configure do |config|
config.ts_header = <<~EOF
// DO NOT EDIT! This file is automatically generated.
import request from './request'
EOF
end
Generate TypeScript:
rails camille:generate
💎 Best Practices We Learned
🎨 1. Dedicated Serializers
Don’t put serialization logic in models. Create dedicated serializers that focus solely on Camille contract compliance.
🔍 2. Test Your Contracts
Write tests that verify your serializers return the exact structure Camille expects. This catches drift early.
🔀 3. Use Union Types
Leverage Camille’s union types (User | { error: String }) to handle success/error responses elegantly.
⏰ 4. String Timestamps
Convert DateTime objects to ISO8601 strings for consistent frontend handling.
🚶♂️ 5. Start Simple
Begin with basic types and schemas, then evolve as your API grows in complexity.
📊 The Impact: Before vs. After
❌ Before Camille:
❌ Manual TypeScript type definitions
❌ Runtime errors from type mismatches
❌ Documentation drift
❌ Time wasted on contract debugging
✅ After Camille:
✅ Single source of truth for API contracts
✅ Automatic TypeScript generation
✅ Runtime validation catches issues immediately
✅ Self-documenting APIs
✅ Confident deployments
⚡ Performance Considerations
You might worry about runtime validation overhead. In our testing:
Development: Invaluable for catching issues early
Test: Perfect for ensuring contract compliance
Production: Consider disabling for performance-critical apps
# Disable in production if needed
config.camille.validate_responses = !Rails.env.production?
🎯 When to Use Camille
✅ Perfect for:
Rails APIs with TypeScript frontends
Teams wanting strong API contracts
Projects where type safety matters
Microservices needing clear interfaces
🤔 Consider alternatives if:
You’re using GraphQL (already type-safe)
Simple APIs with stable contracts
Performance is absolutely critical
🎉 Conclusion
Camille transforms Rails API development by bringing type safety to the Rails-TypeScript boundary. It eliminates a whole class of bugs while making your API more maintainable and self-documenting.
The initial setup requires some discipline – you need to think about your types upfront and maintain serializers. But the payoff in reduced debugging time and increased confidence is enormous.
For our user management API, Camille caught several type mismatches during development that would have been runtime bugs in production. The auto-generated TypeScript types kept our frontend in perfect sync with the backend.
If you’re building Rails APIs with TypeScript frontends, give Camille a try. Your future self (and your team) will thank you.
Want to see the complete implementation? Check out our example repository with a fully working Rails + Camille setup.
Implementing Secure Rails APIs Safeguarding your API isn’t a one-and-done task—it’s a layered approach combining transport encryption, robust authentication, granular authorization, data hygiene, and more. In this post, we’ll walk through twelve core pillars of API security in Rails 8, with code examples and practical tips.
⚙️ 1. Enforce HTTPS Everywhere
Why it matters
Unencrypted HTTP traffic can be intercepted or tampered with. HTTPS (TLS/SSL) ensures end-to-end confidentiality and integrity.
Rails setup
In config/environments/production.rb:
# Forces all access to the app over SSL, uses Strict-Transport-Security, and uses secure cookies.
config.force_ssl = true
This automatically:
Redirects any HTTP request to HTTPS
Sets the Strict-Transport-Security header
Flags cookies as secure
Tip: For development, you can use mkcert or rails dev:ssl to spin up a self-signed certificate.
Generating a Token# app/lib/json_web_token.rb module JsonWebToken SECRET = Rails.application.secret_key_base def self.encode(payload, exp = 24.hours.from_now) payload[:exp] = exp.to_i JWT.encode(payload, SECRET) end end
Decoding & Verificationdef self.decode(token) body = JWT.decode(token, SECRET)[0] HashWithIndifferentAccess.new body rescue JWT::ExpiredSignature, JWT::DecodeError nil end
Tip: Always set a reasonable expiration (exp) and consider rotating your secret_key_base periodically.
🛡️ 3. Authorization with Pundit (or CanCanCan)
Why you need it
Authentication only proves identity; authorization controls what that identity can do. Pundit gives you policy classes that cleanly encapsulate permissions.
Example Pundit Setup
Installbundle add pundit
Include# app/controllers/application_controller.rb include Pundit rescue_from Pundit::NotAuthorizedError, with: :permission_denied def permission_denied render json: { error: 'Forbidden' }, status: :forbidden end
Define a Policy# app/policies/post_policy.rb class PostPolicy < ApplicationPolicy def update? user.admin? || record.user_id == user.id end end
Use in Controllerdef update post = Post.find(params[:id]) authorize post # raises if unauthorized post.update!(post_params) render json: post end
Pro Tip: Keep your policy logic simple. If you see repeated conditional combinations, extract them to helper methods or scopes.
🔐 4. Strong Parameters for Mass-Assignment Safety
The risk
Allowing unchecked request parameters can enable attackers to set fields like admin: true.
Best Practice
def user_params
params.require(:user).permit(:name, :email, :password)
end
Require ensures the key exists.
Permit whitelists only safe attributes.
Note: For deeply-nested or polymorphic data, consider using form objects or contracts (e.g., Reform, dry-validation).
⚠️ 5. Rate Limiting with Rack::Attack
Throttling to the rescue
Protects against brute-force, scraping, and DDoS-style abuse.
Setup Example
# Gemfile
gem 'rack-attack'
# config/initializers/rack_attack.rb
class Rack::Attack
# Throttle all requests by IP (60rpm)
throttle('req/ip', limit: 60, period: 1.minute) do |req|
req.ip
end
# Blocklist abusive IPs
blocklist('block 1.2.3.4') do |req|
req.ip == '1.2.3.4'
end
self.cache.store = ActiveSupport::Cache::MemoryStore.new
end
Tip: Customize by endpoint, user, or even specific header values.
🚨 6. Graceful Error Handling & Logging
Leak no secrets
Catching exceptions ensures you don’t reveal stack traces or sensitive internals.
Bundler Audit: checks for known vulnerable gem versions.
Example RSpec test
require 'rails_helper'
RSpec.describe 'Posts API', type: :request do
it 'rejects unauthenticated access' do
get '/api/posts'
expect(response).to have_http_status(:unauthorized)
end
end
CI Tip: Fail your build if Brakeman warnings exceed zero, or if bundle audit finds CVEs.
🪵 12. Log Responsibly
Don’t log sensitive data (passwords, tokens, etc.)
By combining transport security (HTTPS), stateless authentication (JWT), policy-driven authorization (Pundit), parameter safety, rate limiting, controlled data rendering, hardened headers, and continuous testing, you build a defense-in-depth Rails API. Each layer reduces the attack surface—together, they help ensure your application remains robust against evolving threats.
Modern web and mobile applications demand secure APIs. Traditional session-based authentication falls short in stateless architectures like RESTful APIs. This is where Token-Based Authentication and JWT (JSON Web Token) shine. In this blog post, we’ll explore both approaches, understand how they work, and integrate them into a Rails 8 application.
🔐 1. What is Token-Based Authentication?
Token-based authentication is a stateless security mechanism where the server issues a unique, time-bound token after validating a user’s credentials. The client stores this token (usually in local storage or memory) and sends it along with each API request via HTTP headers.
✅ Key Concepts:
Stateless: No session is stored on the server.
Scalable: Ideal for distributed systems.
Tokens can be opaque (random strings).
Algorithms used:
Token generation commonly uses SecureRandom.
🔎 What is SecureRandom?
SecureRandom is a Ruby module that generates cryptographically secure random numbers and strings. It uses operating system facilities (like /dev/urandom on Unix or CryptGenRandom on Windows) to generate high-entropy values that are safe for use in security-sensitive contexts like tokens, session identifiers, and passwords.
For example:
SecureRandom.hex(32) # generates a 64-character hex string (256 bits)
In Ruby, if you encounter the error:
(irb):5:in '<main>': uninitialized constant SecureRandom (NameError)
Did you mean? SecurityError
It means the SecureRandom module hasn’t been loaded. Although SecureRandom is part of the Ruby Standard Library, it’s not automatically loaded in every environment. You need to explicitly require it.
✅ Solution
Add the following line before using SecureRandom:
require 'securerandom'
Then you can use:
SecureRandom.hex(16) # => "a1b2c3d4e5f6..."
📚 Why This Happens
Ruby does not auto-load all standard libraries to save memory and load time. Modules like SecureRandom, CSV, OpenURI, etc., must be explicitly required if you’re working outside of Rails (like in plain Ruby scripts or IRB).
In a Rails environment, require 'securerandom' is typically handled automatically by the framework.
🛠️ Tip for IRB
If you’re experimenting in IRB (interactive Ruby shell), just run:
require 'securerandom'
SecureRandom.uuid # or any other method
This will eliminate the NameError.
🔒 Why 256 bits?
A 256-bit token offers a massive keyspace of 2^256 combinations, making brute-force attacks virtually impossible. The higher the bit-length, the better the resistance to collision and guessing attacks. Most secure tokens range between 128 and 256 bits. While larger tokens are more secure, they consume more memory and storage.
⚠️ Drawbacks:
SecureRandom tokens are opaque and must be stored on the server (e.g., in a database) for validation.
Token revocation requires server-side tracking.
👷️ Implementing Token-Based Authentication in Rails 8
Step 1: Generate User Model
rails g model User email:string password_digest:string token:string
rails db:migrate
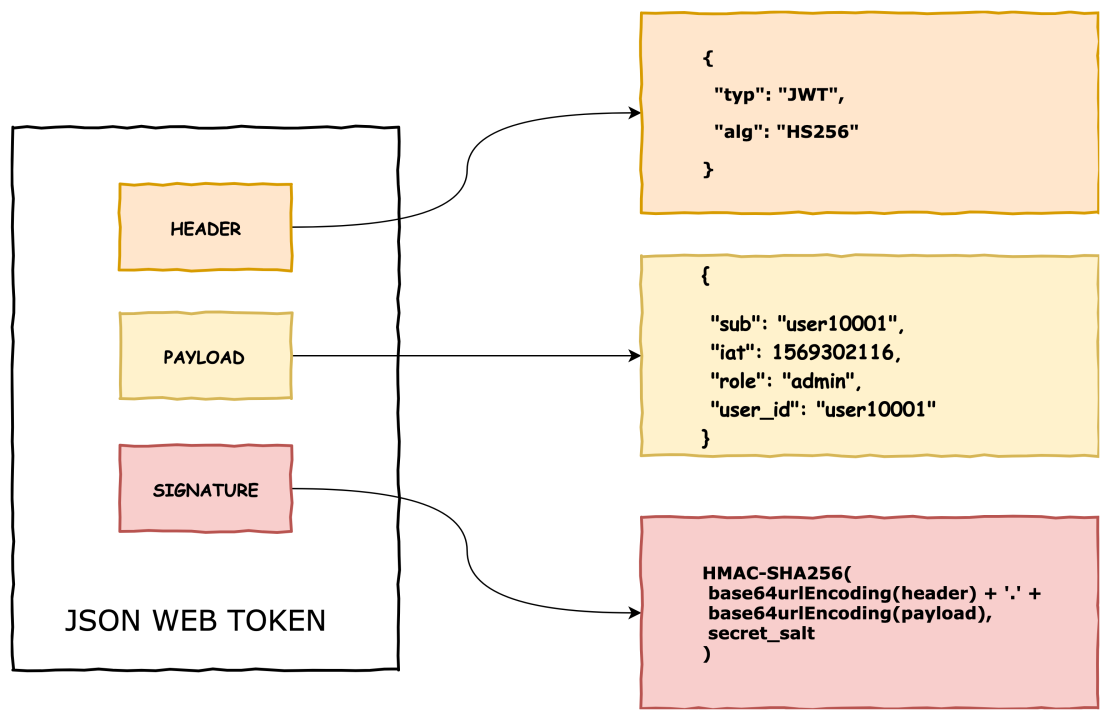
JWT is an open standard for secure information exchange, defined in RFC 7519.
🔗 What is RFC 7519?
RFC 7519 is a specification by the IETF (Internet Engineering Task Force) that defines the structure and rules of JSON Web Tokens. It lays out how to encode claims in a compact, URL-safe format and secure them using cryptographic algorithms. It standardizes the way information is passed between parties as a JSON object.
data = "#{base64_header}.#{base64_payload}"
# => "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoxMjMsImV4cCI6MTcxNzcwMDAwMH0"
🔹 Step 3: Generate Signature using HMAC SHA-256
require 'openssl'
require 'base64'
signature = OpenSSL::HMAC.digest('sha256', secret, data)
# => binary format
encoded_signature = Base64.urlsafe_encode64(signature).gsub('=', '')
# => This is the third part of JWT
# => e.g., "NLoeHhY5jzUgKJGKJq-rK6DTHCKnB7JkPbY3WptZmO8"
✅ Final JWT:
<header>.<payload>.<signature>
Anyone receiving this token can:
Recompute the signature using the same secret key
If it matches the one in the token, it’s valid
If it doesn’t match, the token has been tampered
❓ Is SHA-256 used for encoding or encrypting?
❌ SHA-256 is not encryption. ❌ SHA-256 is not encoding either. ✅ It is a hash function: one-way and irreversible.
It’s used in HMAC to sign data (prove data integrity), not to encrypt or hide data.
✅ Summary:
Purpose
SHA-256 / HMAC SHA-256
Encrypts data?
❌ No
Hides data?
❌ No (use JWE for that)
Reversible?
❌ No
Used in JWT?
✅ Yes (for signature)
Safe?
✅ Very secure if secret is strong
🎯 First: The Big Misunderstanding — Why JWT Isn’t “Encrypted”
JWT is not encrypted by default.
It is just encoded + signed. You can decode the payload, but you cannot forge the signature.
🧠 Difference Between Encoding, Encryption, and Hashing
Concept
Purpose
Reversible?
Example
Encoding
Make data safe for transmission
✅ Yes
Base64
Encryption
Hide data from unauthorized eyes
✅ Yes (with key)
AES, RSA
Hashing
Verify data hasn’t changed
❌ No
SHA-256, bcrypt
🔓 Why can JWT payload be decoded?
Because the payload is only Base64Url encoded, not encrypted.
Example:
{
"user_id": 123,
"role": "admin"
}
When sent in JWT, it becomes:
eyJ1c2VyX2lkIjoxMjMsInJvbGUiOiJhZG1pbiJ9
✅ You can decode it with any online decoder. It’s not private, only structured and verifiable.
🔐 Then What Protects the JWT?
The signature is what protects it.
It proves the payload hasn’t been modified.
The backend signs it with a secret key (HMAC SHA-256 or RS256).
If anyone tampers with the payload and doesn’t have the key, they can’t generate a valid signature.
🧾 Why include the payload inside the JWT?
This is the brilliant part of JWT:
The token is self-contained.
You don’t need a database lookup on every request.
You can extract data like user_id, role, permissions right from the token!
✅ So yes — it’s just a token, but a smart token with claims (data) you can trust.
This is ideal for stateless APIs.
💡 Then why not send payload in POST body?
You absolutely can — and often do, for data-changing operations (like submitting forms). But that’s request data, not authentication info.
JWT serves as the proof of identity and permission, like an ID card.
You put it in the Authorization header, not the body.
📦 Is it okay to send large payloads in JWT?
Technically, yes, but not recommended. Why?
JWTs are sent in every request header — that adds bloat.
Bigger tokens = slower transmission + possible header size limits.
If your payload is very large, use a token to reference it in DB or cache, not store everything in the token.
⚠️ If the secret doesn’t match?
Yes — that means someone altered the token (probably the payload).
If user_id was changed to 999, but they can’t recreate a valid signature (they don’t have the secret), the backend rejects the token.
🔐 Then When Should We Encrypt?
JWT only signs, but not encrypts.
If you want to hide the payload:
Use JWE (JSON Web Encryption) — a different standard.
Or: don’t put sensitive data in JWT at all.
🔁 Summary: Why JWT is a Big Deal
✅ Self-contained authentication
✅ Stateless (no DB lookups)
✅ Signed — so payload can’t be tampered
❌ Not encrypted — anyone can see payload
⚠️ Keep payload small and non-sensitive
🧠 One Last Time: Summary Table
Topic
JWT
POST Body
Used for
Authentication/identity
Submitting request data
Data type
Claims (user_id, role)
Form/input data
Seen by user?
Yes (Base64-encoded)
Yes
Security
Signature w/ secret
HTTPS
Stored where?
Usually in browser (e.g. localStorage, cookie)
N/A
Think of JWT like a sealed letter:
Anyone can read the letter (payload).
But they can’t forge the signature/stamp.
The receiver checks the signature to verify the letter is real and unmodified.
🧨 Yes, JWT Payload is Visible — and That Has Implications
The payload of a JWT is only Base64Url encoded, not encrypted.
This means anyone who has the token (e.g., a user, a man-in-the-middle without HTTPS, or a frontend dev inspecting in the browser) can decode it and see:
It doesn’t prevent others from reading the payload, but it prevents them from modifying it (thanks to the signature).
It allows stateless auth without needing a DB lookup on every request.
It’s useful for microservices where services can verify tokens without a central auth store.
🧰 Best Practices for JWT Payloads
Treat the payload as public data.
Ask yourself: “Is it okay if the user sees this?”
Never trust the token blindly on the client.
Always verify the signature and claims server-side.
Use only identifiers, not sensitive context.
For example, instead of embedding full permissions: { "user_id": 123, "role": "admin" } fetch detailed permissions on the backend based on role.
Encrypt the token if sensitive data is needed.
Use JWE (JSON Web Encryption), or
Store sensitive data on the server and pass only a reference (like a session id or user_id).
📌 Bottom Line
JWT is not private. It is only protected from tampering, not from reading.
So if you use it in your app, make sure the payload contains only safe, public information, and that any sensitive logic (like permission checks) happens on the server.
# app/services/json_web_token.rb
class JsonWebToken
def self.encode(payload, exp = 24.hours.from_now)
payload[:exp] = exp.to_i
JWT.encode(payload, JWT_SECRET, 'HS256')
end
def self.decode(token)
body = JWT.decode(token, JWT_SECRET, true, { algorithm: 'HS256' })[0]
HashWithIndifferentAccess.new body
rescue
nil
end
end
Step 4: Sessions Controller for JWT
# app/controllers/api/v1/sessions_controller.rb
class Api::V1::SessionsController < ApplicationController
def create
user = User.find_by(email: params[:email])
if user&.authenticate(params[:password])
token = JsonWebToken.encode(user_id: user.id)
render json: { jwt: token }, status: :ok
else
render json: { error: 'Invalid credentials' }, status: :unauthorized
end
end
end
Step 5: Authentication in Application Controller
# app/controllers/application_controller.rb
class ApplicationController < ActionController::API
before_action :authenticate_request
def authenticate_request
header = request.headers['Authorization']
token = header.split(' ').last if header
decoded = JsonWebToken.decode(token)
@current_user = User.find_by(id: decoded[:user_id]) if decoded
render json: { error: 'Unauthorized' }, status: :unauthorized unless @current_user
end
end
🌍 How Token-Based Authentication Secures APIs
🔒 Benefits:
Stateless: Scales well
Works across domains
Easy to integrate with mobile/web clients
JWT is tamper-proof and verifiable
⚡ Drawbacks:
Token revocation is hard without server tracking (esp. JWT)
Long-lived tokens can be risky if leaked
Requires HTTPS always
📆 Final Thoughts
For most Rails API-only apps, JWT is the go-to solution due to its stateless, self-contained nature. However, for simpler setups or internal tools, basic token-based methods can still suffice. Choose based on your app’s scale, complexity, and security needs.
Ruby on Rails continues to be one of the most popular web development frameworks, powering applications from startups to enterprise-level systems. Whether you’re starting your Rails journey or looking to master advanced concepts, understanding core Rails principles is essential for building robust, scalable applications.
This comprehensive mastery guide covers 50 essential Ruby on Rails concepts with detailed explanations, real-world examples, and production-ready code snippets. From fundamental MVC patterns to advanced topics like multi-tenancy and performance monitoring, this guide will transform you into a confident Rails developer.
🏗️ Core Rails Concepts
💎 1. Explain the MVC Pattern in Rails
MVC is an architectural pattern that separates responsibilities into three interconnected components:
Model – Manages data and business logic
View – Presents data to the user (UI)
Controller – Orchestrates requests, talks to models, and renders views
This separation keeps our code organized, testable, and maintainable.
🔧 Components & Responsibilities
Component
Responsibility
Rails Class
Model
• Data persistence (tables, rows)
app/models/*.rb (e.g. Post)
• Business rules & validations
View
• User interface (HTML, ERB, JSON, etc.)
app/views/*/*.html.erb
• Presentation logic (formatting, helpers)
Controller
• Receives HTTP requests
app/controllers/*_controller.rb
• Invokes models & selects views
• Handles redirects and status codes
🛠 How It Works: A Request Cycle
Client → Request Browser sends, for example, GET /posts/1.
Router → Controller config/routes.rb maps to PostsController#show.
Controller → Modelclass PostsController < ApplicationController def show @post = Post.find(params[:id]) end end
Controller → View By default, renders app/views/posts/show.html.erb, with access to @post.
View → Response ERB template generates HTML, sent back to the browser.
✅ Example: Posts Show Action
1. Model (app/models/post.rb)
class Post < ApplicationRecord
validates :title, :body, presence: true
belongs_to :author, class_name: "User"
end
Displays data and runs helper methods (simple_format).
🔁 Why MVC Matters
Separation of Concerns
Models don’t care about HTML.
Views don’t talk to the database directly.
Controllers glue things together.
Testability
You can write unit tests for models, view specs, and controller specs independently.
Scalability
As your app grows, you know exactly where to add new database logic (models), new pages (views), or new routes/actions (controllers).
🚀 Summary
Layer
File Location
Key Role
Model
app/models/*.rb
Data & business logic
View
app/views/<controller>/*.erb
Presentation & UI
Controller
app/controllers/*_controller.rb
Request handling & flow control
With MVC in Rails, each piece stays focused on its own job—making your code cleaner and easier to manage.
💎 2. What Is Convention over Configuration?
Description
Convention over Configuration (CoC) is a design principle that minimizes the number of decisions developers need to make by providing sensible defaults.
The framework gives you smart defaults—like expected names and file locations—so you don’t have to set up every detail yourself. You just follow its conventions unless you need something special.
Benefits
Less boilerplate: You write minimal setup code.
Faster onboarding: New team members learn the “Rails way” instead of endless configuration options.
Consistency: Codebases follow uniform patterns, making them easier to read and maintain.
Productivity boost: Focus on business logic instead of configuration files.
How Rails Leverages CoC
Example 1: Model–Table Mapping
Convention: A User model maps to the users database table.
No config needed: You don’t need to declare self.table_name = "users" unless your table name differs.
# app/models/user.rb
class User < ApplicationRecord
# Rails assumes: table name = "users"
end
No config needed: You don’t need to call render "posts/show" unless you want a different template.
# app/controllers/posts_controller.rb
class PostsController < ApplicationController
def show
@post = Post.find(params[:id])
# Rails auto-renders "posts/show.html.erb"
end
end
When to Override
Custom Table Names
class LegacyUser < ApplicationRecord
self.table_name = "legacy_users"
end
Custom Render Paths
class DashboardController < ApplicationController
def index
render template: "admin/dashboard/index"
end
end
Use overrides sparingly, only when your domain truly diverges from Rails’ defaults.
Key Takeaways
Summary
Convention over Configuration means “adhere to framework defaults unless there’s a strong reason not to.”
Rails conventions cover naming, file structure, routing, ORM mappings, and more.
Embracing these conventions leads to cleaner, more consistent, and less verbose code.
Answer: ActiveRecord provides several association types:
class User < ApplicationRecord
has_many :posts, dependent: :destroy
has_many :comments, through: :posts
has_one :profile
belongs_to :organization, optional: true
end
class Post < ApplicationRecord
belongs_to :user
has_many :comments
has_and_belongs_to_many :tags
end
class Comment < ApplicationRecord
belongs_to :post
belongs_to :user
end
Answer: Polymorphic associations allow a model to belong to more than one other model on a single association:
class Comment < ApplicationRecord
belongs_to :commentable, polymorphic: true
end
class Post < ApplicationRecord
has_many :comments, as: :commentable
end
class Photo < ApplicationRecord
has_many :comments, as: :commentable
end
# Migration
class CreateComments < ActiveRecord::Migration[7.0]
def change
create_table :comments do |t|
t.text :content
t.references :commentable, polymorphic: true, null: false
t.timestamps
end
end
end
# Usage
post = Post.first
post.comments.create(content: "Great post!")
photo = Photo.first
photo.comments.create(content: "Nice photo!")
# Querying
Comment.where(commentable_type: 'Post')
💎 6. What are Single Table Inheritance(STI) and its alternatives?
Answer: STI stores multiple models in one table using a type column:
# STI Implementation
class Animal < ApplicationRecord
validates :type, presence: true
end
class Dog < Animal
def bark
"Woof!"
end
end
class Cat < Animal
def meow
"Meow!"
end
end
# Migration
class CreateAnimals < ActiveRecord::Migration[7.0]
def change
create_table :animals do |t|
t.string :type, null: false
t.string :name
t.string :breed # Only for dogs
t.boolean :indoor # Only for cats
t.timestamps
end
add_index :animals, :type
end
end
# Alternative: Multiple Table Inheritance (MTI)
class Animal < ApplicationRecord
has_one :dog
has_one :cat
end
class Dog < ApplicationRecord
belongs_to :animal
end
class Cat < ApplicationRecord
belongs_to :animal
end
💎 7. What are Database Migrations?
Answer: Migrations are Ruby classes that define database schema changes in a version-controlled way.
class CreateUsers < ActiveRecord::Migration[7.0]
def change
create_table :users do |t|
t.string :name, null: false
t.string :email, null: false, index: { unique: true }
t.timestamps
end
end
end
# Adding a column later
class AddAgeToUsers < ActiveRecord::Migration[7.0]
def change
add_column :users, :age, :integer
end
end
💎 8. Explain Database Transactions and Isolation Levels
Answer: Transactions ensure data consistency and handle concurrent access:
# Basic transaction
ActiveRecord::Base.transaction do
user = User.create!(name: "John")
user.posts.create!(title: "First Post")
# If any operation fails, everything rolls back
end
# Nested transactions with savepoints
User.transaction do
user = User.create!(name: "John")
begin
User.transaction(requires_new: true) do
# This creates a savepoint
user.posts.create!(title: "") # This will fail
end
rescue ActiveRecord::RecordInvalid
# Inner transaction rolled back, but outer continues
end
user.posts.create!(title: "Valid Post") # This succeeds
end
# Manual transaction control
ActiveRecord::Base.transaction do
user = User.create!(name: "John")
if some_condition
raise ActiveRecord::Rollback # Forces rollback
end
end
# Isolation levels (database-specific)
User.transaction(isolation: :serializable) do
# Highest isolation level
end
💎 8. Explain Database Indexing in Rails
Answer: Indexes improve query performance by creating faster lookup paths:
class AddIndexesToUsers < ActiveRecord::Migration[7.0]
def change
add_index :users, :email, unique: true
add_index :users, [:first_name, :last_name]
add_index :posts, :user_id
add_index :posts, [:user_id, :created_at]
end
end
# In model validations that should have indexes
class User < ApplicationRecord
validates :email, uniqueness: true # Should have unique index
end
Answer: Use parameterized queries and ActiveRecord methods:
# BAD: Vulnerable to SQL injection
User.where("name = '#{params[:name]}'")
# GOOD: Parameterized queries
User.where(name: params[:name])
User.where("name = ?", params[:name])
User.where("name = :name", name: params[:name])
# For complex queries
User.where("created_at > ? AND status = ?", 1.week.ago, 'active')
💎 9. Explain N+1 Query Problem and Solutions
The N+1 query problem is a performance anti-pattern in database access—especially common in Rails when using Active Record. It occurs when your application executes 1 query to fetch a list of records and then N additional queries to fetch associated records for each item in the list.
🧨 What is the N+1 Query Problem?
Imagine you fetch all posts, and for each post, you access its author. Without optimization, Rails will execute:
1 query to fetch all posts
N queries (one per post) to fetch each author individually
→ That’s N+1 total queries instead of the ideal 2.
❌ Example 1 – Posts and Authors (N+1)
# model
class Post
belongs_to :author
end
# controller
@posts = Post.all
# view (ERB or JSON)
@posts.each do |post|
puts post.author.name
end
🔍 Generated SQL:
SELECT * FROM posts;
SELECT * FROM users WHERE id = 1;
SELECT * FROM users WHERE id = 2;
SELECT * FROM users WHERE id = 3;
...
If you have 100 posts, that’s 101 queries! 😬
✅ Solution: Use includes to Eager Load
@posts = Post.includes(:author)
Now Rails loads all authors in one additional query:
SELECT * FROM posts;
SELECT * FROM users WHERE id IN (1, 2, 3, ...);
Only 2 queries no matter how many posts!
❌ Example 2 – Comments and Post Titles (N+1)
# model
class Comment
belongs_to :post
end
# controller
@comments = Comment.all
# view (ERB or JSON)
@comments.each do |comment|
puts comment.post.title
end
Each call to comment.post will trigger a separate DB query.
✅ Fix: Eager Load with includes
@comments = Comment.includes(:post)
Rails will now load posts in a single query, fixing the N+1 issue.
🔄 Other Fixes
Fix
Usage
includes(:assoc)
Eager loads associations (default lazy join)
preload(:assoc)
Always runs a separate query for association
eager_load(:assoc)
Uses LEFT OUTER JOIN to load in one query
joins(:assoc)
For filtering/sorting only, not eager loading
🧪 How to Detect N+1 Problems
Use tools like:
✅ Bullet gem – shows alerts in dev when N+1 queries happen
✅ New Relic / Skylight / Scout – for performance monitoring
📝 Summary
🔥 Problem
❌ Post.all + post.author in loop
✅ Solution
Post.includes(:author)
✅ Benefit
Prevents N+1 DB queries, boosts performance
✅ Tooling
Bullet gem to catch during dev
💎 9. What Are Scopes 🎯 in ActiveRecord?
Scopes in Rails are custom, chainable queries defined on your model. They let you write readable and reusable query logic.
Instead of repeating complex conditions in controllers or models, you wrap them in scopes.
✅ Why Use Scopes?
Clean and DRY code
Chainable like .where, .order
Improves readability and maintainability
Keeps controllers slim
🔧 How to Define a Scope?
Use the scope method in your model:
class Product < ApplicationRecord
scope :available, -> { where(status: 'available') }
scope :recent, -> { order(created_at: :desc) }
end
🧪 How to Use a Scope?
Product.available # SELECT * FROM products WHERE status = 'available';
Product.recent # SELECT * FROM products ORDER BY created_at DESC;
Product.available.recent # Chained query!
👉 Example: A Blog App with Scopes
📝 Post model
class Post < ApplicationRecord
scope :published, -> { where(published: true) }
scope :by_author, ->(author_id) { where(author_id: author_id) }
scope :recent, -> { order(created_at: :desc) }
end
💡 Usage in Controller
# posts_controller.rb
@posts = Post.published.by_author(current_user.id).recent
# Behind
# 🔍 Parameterized SQL
SELECT "posts".*
FROM "posts"
WHERE "posts"."published" = $1
AND "posts"."author_id" = $2
ORDER BY "posts"."created_at" DESC
# 📥 Bound Values
# $1 = true, $2 = current_user.id (e.g. 5)
# with Interpolated Values
SELECT "posts".*
FROM "posts"
WHERE "posts"."published" = TRUE
AND "posts"."author_id" = 5
ORDER BY "posts"."created_at" DESC;
Answer: Rails follows REST conventions for resource routing:
# config/routes.rb
Rails.application.routes.draw do
resources :posts do
resources :comments, except: [:show]
member do
patch :publish
end
collection do
get :drafts
end
end
end
# Generated routes:
# GET /posts (index)
# GET /posts/new (new)
# POST /posts (create)
# GET /posts/:id (show)
# GET /posts/:id/edit (edit)
# PATCH /posts/:id (update)
# DELETE /posts/:id (destroy)
# PATCH /posts/:id/publish (custom member)
# GET /posts/drafts (custom collection)
# Built-in constraints
Rails.application.routes.draw do
# Subdomain constraint
constraints subdomain: 'api' do
namespace :api do
resources :users
end
end
# IP constraint
constraints ip: /192\.168\.1\.\d+/ do
get '/admin' => 'admin#index'
end
# Lambda constraints
constraints ->(req) { req.remote_ip == '127.0.0.1' } do
mount Sidekiq::Web => '/sidekiq'
end
# Parameter format constraints
get '/posts/:id', to: 'posts#show', constraints: { id: /\d+/ }
get '/posts/:slug', to: 'posts#show_by_slug'
end
# Custom constraint classes
class MobileConstraint
def matches?(request)
request.user_agent =~ /Mobile|webOS/
end
end
class AdminConstraint
def matches?(request)
return false unless request.session[:user_id]
User.find(request.session[:user_id]).admin?
end
end
# Usage
Rails.application.routes.draw do
constraints MobileConstraint.new do
root 'mobile#index'
end
constraints AdminConstraint.new do
mount Sidekiq::Web => '/sidekiq'
end
root 'home#index' # Default route
end
💎 16. Explain Mass Assignment Protection
Answer: Prevent unauthorized attribute updates using Strong Parameters:
# Model with attr_accessible (older Rails)
class User < ApplicationRecord
attr_accessible :name, :email # Only these can be mass assigned
end
# Modern Rails with Strong Parameters
class UsersController < ApplicationController
def update
if @user.update(user_params)
redirect_to @user
else
render :edit
end
end
private
def user_params
params.require(:user).permit(:name, :email)
# :admin, :role are not permitted
end
end
💎 10. What Are Strong Parameters in Rails?
🔐 Definition
Strong Parameters are a feature in Rails that prevents mass assignment vulnerabilities by explicitly permitting only the safe parameters from the params hash (are allowed to pass in) before saving/updating a model.
⚠️ Why They’re Important
Before Rails 4, using code like this was dangerous:
User.create(params[:user])
If the form included admin: true, any user could make themselves an admin!
But post_params only allows title and body, so admin is discarded silently.
✅ Summary Table
✅ Purpose
✅ How It Helps
Prevents mass assignment
Avoids unwanted model attributes from being set
Requires explicit whitelisting
Forces you to permit only known-safe keys
Works with nested data
Supports permit(sub_attributes: [...])
💎 11. Explain Before/After Actions (Filters)
Answer: Filters run code before, after, or around controller actions:
⚙️ What Are Before/After Actions in Rails?
🧼 Definition
Before, after, and around filters are controller-level callbacks that run before or after controller actions. They help you extract repeated logic, like authentication, logging, or setup.
⏱️ Types of Filters
Filter Type
When It Runs
Common Use
before_action
Before the action executes
Set variables, authenticate user
after_action
After the action finishes
Log activity, clean up data
around_action
Wraps around the action
Benchmarking, transactions
🛠️ Example Controller Using Filters
# controllers/posts_controller.rb
class PostsController < ApplicationController
before_action :set_post, only: [:show, :edit, :update, :destroy]
before_action :authenticate_user!
after_action :log_post_access, only: :show
def show
# @post is already set by before_action
end
def edit
# @post is already set by before_action
end
def update
if @post.update(post_params)
redirect_to @post
else
render :edit
end
end
def destroy
if @post.destroy
.....
end
private
def set_post
@post = Post.find(params[:id])
end
def authenticate_user!
redirect_to login_path unless current_user
end
def log_post_access
Rails.logger.info "Post #{@post.id} was viewed by #{current_user&.email || 'guest'}"
end
def post_params
params.require(:post).permit(:title, :body)
end
end
# Fragment Caching
<% cache @post do %>
<%= render @post %>
<% end %>
# Russian Doll Caching
<% cache [@post, @post.comments.maximum(:updated_at)] do %>
<%= render @post %>
<%= render @post.comments %>
<% end %>
# Low-level caching
class PostsController < ApplicationController
def expensive_operation
Rails.cache.fetch("expensive_operation_#{params[:id]}", expires_in: 1.hour) do
# Expensive computation here
calculate_complex_data
end
end
end
# Query caching (automatic in Rails)
# HTTP caching
class PostsController < ApplicationController
def show
@post = Post.find(params[:id])
if stale?(last_modified: @post.updated_at, etag: @post)
# Render the view
end
end
end
💎 18. What is Eager Loading and when to use it?
Answer: Eager loading reduces database queries by loading associated records upfront:
# includes: Loads all data in separate queries
posts = Post.includes(:author, :comments)
# joins: Uses SQL JOIN (no access to associated records)
posts = Post.joins(:author).where(authors: { active: true })
# preload: Always uses separate queries
posts = Post.preload(:author, :comments)
# eager_load: Always uses LEFT JOIN
posts = Post.eager_load(:author, :comments)
# Use when you know you'll access the associations
posts.each do |post|
puts "#{post.title} by #{post.author.name}"
puts "Comments: #{post.comments.count}"
end
💎 19. How do you optimize database queries?
Answer: Several strategies for query optimization:
# Use select to limit columns
User.select(:id, :name, :email).where(active: true)
# Use pluck for single values
User.where(active: true).pluck(:email)
# Use exists? instead of present?
User.where(role: 'admin').exists? # vs .present?
# Use counter_cache for counts
class Post < ApplicationRecord
belongs_to :user, counter_cache: true
end
# Migration to add counter cache
add_column :users, :posts_count, :integer, default: 0
# Use find_each for large datasets
User.find_each(batch_size: 1000) do |user|
user.update_some_attribute
end
# Database indexes for frequently queried columns
add_index :posts, [:user_id, :published_at]
💎 20. Explain different types of tests in Rails
Answer: Rails supports multiple testing levels:
# Unit Tests (Model tests)
require 'test_helper'
class UserTest < ActiveSupport::TestCase
test "should not save user without email" do
user = User.new
assert_not user.save
end
test "should save user with valid attributes" do
user = User.new(name: "John", email: "john@example.com")
assert user.save
end
end
# Integration Tests (Controller tests)
class UsersControllerTest < ActionDispatch::IntegrationTest
test "should get index" do
get users_url
assert_response :success
end
test "should create user" do
assert_difference('User.count') do
post users_url, params: { user: { name: "John", email: "john@test.com" } }
end
assert_redirected_to user_url(User.last)
end
end
# System Tests (Feature tests)
class UsersSystemTest < ApplicationSystemTestCase
test "creating a user" do
visit users_path
click_on "New User"
fill_in "Name", with: "John Doe"
fill_in "Email", with: "john@example.com"
click_on "Create User"
assert_text "User was successfully created"
end
end
💎 21. What are Fixtures vs Factories?
Answer: Both provide test data, but with different approaches:
# Fixtures (YAML files)
# test/fixtures/users.yml
john:
name: John Doe
email: john@example.com
jane:
name: Jane Smith
email: jane@example.com
# Usage
user = users(:john)
# Factories (using FactoryBot)
# test/factories/users.rb
FactoryBot.define do
factory :user do
name { "John Doe" }
email { Faker::Internet.email }
trait :admin do
role { 'admin' }
end
factory :admin_user, traits: [:admin]
end
end
# Usage
user = create(:user)
admin = create(:admin_user)
build(:user) # builds but doesn't save
💎 22. Explain ActiveJob and Background Processing
Answer: ActiveJob provides a unified interface for background jobs:
# Job class
class EmailJob < ApplicationJob
queue_as :default
retry_on StandardError, wait: 5.seconds, attempts: 3
def perform(user_id, email_type)
user = User.find(user_id)
UserMailer.send(email_type, user).deliver_now
end
end
# Enqueue jobs
EmailJob.perform_later(user.id, :welcome)
EmailJob.set(wait: 1.hour).perform_later(user.id, :reminder)
# With Sidekiq
class EmailJob < ApplicationJob
queue_as :high_priority
sidekiq_options retry: 3, backtrace: true
def perform(user_id)
# Job logic
end
end
💎 23. What are Rails Engines?
Answer: Engines are miniature applications that provide functionality to host applications:
# Creating an engine
rails plugin new blog --mountable
# Engine structure
module Blog
class Engine < ::Rails::Engine
isolate_namespace Blog
config.generators do |g|
g.test_framework :rspec
end
end
end
# Mounting in host app
Rails.application.routes.draw do
mount Blog::Engine => "/blog"
end
# Engine can have its own models, controllers, views
# app/models/blog/post.rb
module Blog
class Post < ApplicationRecord
end
end
💎 24. Explain Action Cable and WebSockets
Answer: Action Cable integrates WebSockets with Rails for real-time features:
Answer: Service objects encapsulate business logic that doesn’t belong in models or controllers:
class UserRegistrationService
include ActiveModel::Model
attr_accessor :name, :email, :password
validates :email, presence: true, format: { with: URI::MailTo::EMAIL_REGEXP }
validates :password, length: { minimum: 8 }
def call
return false unless valid?
ActiveRecord::Base.transaction do
user = create_user
send_welcome_email(user)
create_default_profile(user)
user
end
rescue => e
errors.add(:base, e.message)
false
end
private
def create_user
User.create!(name: name, email: email, password: password)
end
def send_welcome_email(user)
UserMailer.welcome(user).deliver_later
end
def create_default_profile(user)
user.create_profile!(name: name)
end
end
# Usage
service = UserRegistrationService.new(user_params)
if service.call
redirect_to dashboard_path
else
@errors = service.errors
render :new
end
💎 27. What are Rails Concerns?
Answer: Concerns provide a way to share code between models or controllers:
# app/models/concerns/timestampable.rb
module Timestampable
extend ActiveSupport::Concern
included do
scope :recent, -> { order(created_at: :desc) }
scope :from_last_week, -> { where(created_at: 1.week.ago..) }
end
class_methods do
def cleanup_old_records
where('created_at < ?', 1.year.ago).destroy_all
end
end
def age_in_days
(Time.current - created_at) / 1.day
end
end
# Usage in models
class Post < ApplicationRecord
include Timestampable
end
class Comment < ApplicationRecord
include Timestampable
end
# Controller concerns
module Authentication
extend ActiveSupport::Concern
included do
before_action :authenticate_user!
end
private
def authenticate_user!
redirect_to login_path unless user_signed_in?
end
end
💎 28. Explain Rails API Mode
Answer: Rails can run in API-only mode for building JSON APIs:
# Generate API-only application
rails new my_api --api
# API controller
class ApplicationController < ActionController::API
include ActionController::HttpAuthentication::Token::ControllerMethods
before_action :authenticate
private
def authenticate
authenticate_or_request_with_http_token do |token, options|
ApiKey.exists?(token: token)
end
end
end
class UsersController < ApplicationController
def index
users = User.all
render json: users, each_serializer: UserSerializer
end
def create
user = User.new(user_params)
if user.save
render json: user, serializer: UserSerializer, status: :created
else
render json: { errors: user.errors }, status: :unprocessable_entity
end
end
end
# Serializer
class UserSerializer < ActiveModel::Serializer
attributes :id, :name, :email, :created_at
has_many :posts
end
💎 29. What is Rails Autoloading?
Answer: Rails automatically loads classes and modules on demand:
# Rails autoloading rules:
# app/models/user.rb -> User
# app/models/admin/user.rb -> Admin::User
# app/controllers/posts_controller.rb -> PostsController
# Eager loading in production
config.eager_load = true
# Custom autoload paths
config.autoload_paths << Rails.root.join('lib')
# Zeitwerk (Rails 6+) autoloader
config.autoloader = :zeitwerk
# Reloading in development
config.cache_classes = false
config.reload_classes_only_on_change = true
💎 30. Explain Rails Credentials and Secrets
Answer: Rails provides encrypted credentials for sensitive data:
# Edit credentials
rails credentials:edit
# credentials.yml.enc content
secret_key_base: abc123...
database:
password: secretpassword
aws:
access_key_id: AKIAIOSFODNN7EXAMPLE
secret_access_key: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
# Usage in application
Rails.application.credentials.database[:password]
Rails.application.credentials.aws[:access_key_id]
# Environment-specific credentials
rails credentials:edit --environment production
# In production
RAILS_MASTER_KEY=your_master_key rails server
💎 31. How do you handle file uploads in Rails?
Answer: Using Active Storage (Rails 5.2+):
# Model
class User < ApplicationRecord
has_one_attached :avatar
has_many_attached :documents
validate :acceptable_avatar
private
def acceptable_avatar
return unless avatar.attached?
unless avatar.blob.byte_size <= 1.megabyte
errors.add(:avatar, "is too big")
end
acceptable_types = ["image/jpeg", "image/png"]
unless acceptable_types.include?(avatar.blob.content_type)
errors.add(:avatar, "must be a JPEG or PNG")
end
end
end
# Controller
def user_params
params.require(:user).permit(:name, :email, :avatar, documents: [])
end
# View
<%= form_with model: @user do |form| %>
<%= form.file_field :avatar %>
<%= form.file_field :documents, multiple: true %>
<% end %>
# Display
<%= image_tag @user.avatar if @user.avatar.attached? %>
<%= link_to "Download", @user.avatar, download: true %>
💎32. What are Rails Callbacks and when to use them?
Answer: Callbacks are hooks that run at specific points in an object’s lifecycle:
class User < ApplicationRecord
before_validation :normalize_email
before_create :generate_auth_token
after_create :send_welcome_email
before_destroy :cleanup_associated_data
private
def normalize_email
self.email = email.downcase.strip if email.present?
end
def generate_auth_token
self.auth_token = SecureRandom.hex(32)
end
def send_welcome_email
UserMailer.welcome(self).deliver_later
end
def cleanup_associated_data
# Clean up associated records
posts.destroy_all
end
end
# Conditional callbacks
class Post < ApplicationRecord
after_save :update_search_index, if: :published?
before_destroy :check_if_deletable, unless: :admin_user?
end
💎 36. How do you handle Race Conditions in Rails?
Answer: Several strategies to prevent race conditions:
# 1. Optimistic Locking
class Post < ApplicationRecord
# Migration adds lock_version column
end
# Usage
post = Post.find(1)
post.title = "Updated Title"
begin
post.save!
rescue ActiveRecord::StaleObjectError
# Handle conflict - reload and retry
post.reload
post.title = "Updated Title"
post.save!
end
# 2. Pessimistic Locking
Post.transaction do
post = Post.lock.find(1) # SELECT ... FOR UPDATE
post.update!(view_count: post.view_count + 1)
end
# 3. Database constraints and unique indexes
class User < ApplicationRecord
validates :email, uniqueness: true
end
# Migration with unique constraint
add_index :users, :email, unique: true
# 4. Atomic operations
# BAD: Race condition possible
user = User.find(1)
user.update!(balance: user.balance + 100)
# GOOD: Atomic update
User.where(id: 1).update_all("balance = balance + 100")
# 5. Redis for distributed locks
class DistributedLock
def self.with_lock(key, timeout: 10)
lock_acquired = Redis.current.set(key, "locked", nx: true, ex: timeout)
if lock_acquired
begin
yield
ensure
Redis.current.del(key)
end
else
raise "Could not acquire lock"
end
end
end
💎 38. What are Rails Generators and how do you create custom ones?
Answer: Generators automate file creation and boilerplate code:
# Built-in generators
rails generate model User name:string email:string
rails generate controller Users index show
rails generate migration AddAgeToUsers age:integer
# Custom generator
# lib/generators/service/service_generator.rb
class ServiceGenerator < Rails::Generators::NamedBase
source_root File.expand_path('templates', __dir__)
argument :methods, type: :array, default: [], banner: "method method"
class_option :namespace, type: :string, default: "Services"
def create_service_file
template "service.rb.erb", "app/services/#{file_name}_service.rb"
end
def create_service_test
template "service_test.rb.erb", "test/services/#{file_name}_service_test.rb"
end
private
def service_class_name
"#{class_name}Service"
end
def namespace_class
options[:namespace]
end
end
# Usage
rails generate service UserRegistration create_user send_email --namespace=Auth
💎 39. Explain Rails Middleware and how to create custom middleware
Answer: Middleware sits between the web server and Rails application:
# View current middleware stack
rake middleware
# Custom middleware
class RequestTimingMiddleware
def initialize(app)
@app = app
end
def call(env)
start_time = Time.current
# Process request
status, headers, response = @app.call(env)
end_time = Time.current
duration = ((end_time - start_time) * 1000).round(2)
# Add timing header
headers['X-Request-Time'] = "#{duration}ms"
# Log slow requests
if duration > 1000
Rails.logger.warn "Slow request: #{env['REQUEST_METHOD']} #{env['PATH_INFO']} took #{duration}ms"
end
[status, headers, response]
end
end
# Authentication middleware
class ApiAuthenticationMiddleware
def initialize(app)
@app = app
end
def call(env)
request = Rack::Request.new(env)
if api_request?(request)
return unauthorized_response unless valid_api_key?(request)
end
@app.call(env)
end
private
def api_request?(request)
request.path.start_with?('/api/')
end
def valid_api_key?(request)
api_key = request.headers['X-API-Key']
ApiKey.exists?(key: api_key, active: true)
end
def unauthorized_response
[401, {'Content-Type' => 'application/json'}, ['{"error": "Unauthorized"}']]
end
end
# Register middleware in application.rb
config.middleware.use RequestTimingMiddleware
config.middleware.insert_before ActionDispatch::Static, ApiAuthenticationMiddleware
# Conditional middleware
if Rails.env.development?
config.middleware.use MyDevelopmentMiddleware
end
💎 40. How do you implement Full-Text Search in Rails?
Answer: Several approaches for implementing search functionality:
# 1. Database-specific full-text search (PostgreSQL)
class Post < ApplicationRecord
include PgSearch::Model
pg_search_scope :search_by_content,
against: [:title, :content],
using: {
tsearch: {
prefix: true,
any_word: true
},
trigram: {
threshold: 0.3
}
}
end
# Migration for PostgreSQL
class AddSearchToPost < ActiveRecord::Migration[7.0]
def up
execute "CREATE EXTENSION IF NOT EXISTS pg_trgm;"
execute "CREATE EXTENSION IF NOT EXISTS unaccent;"
add_column :posts, :searchable, :tsvector
add_index :posts, :searchable, using: :gin
execute <<-SQL
CREATE OR REPLACE FUNCTION update_post_searchable() RETURNS trigger AS $$
BEGIN
NEW.searchable := to_tsvector('english', coalesce(NEW.title, '') || ' ' || coalesce(NEW.content, ''));
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER update_post_searchable_trigger
BEFORE INSERT OR UPDATE ON posts
FOR EACH ROW EXECUTE FUNCTION update_post_searchable();
SQL
end
end
# 2. Elasticsearch with Searchkick
class Post < ApplicationRecord
searchkick word_start: [:title], highlight: [:title, :content]
def search_data
{
title: title,
content: content,
author: author.name,
published_at: published_at,
tags: tags.pluck(:name)
}
end
end
# Usage
results = Post.search("ruby rails",
fields: [:title^2, :content],
highlight: true,
aggs: {
tags: {},
authors: { field: "author" }
}
)
# 3. Simple database search with scopes
class Post < ApplicationRecord
scope :search, ->(term) {
return none if term.blank?
terms = term.split.map { |t| "%#{t}%" }
query = terms.map { "title ILIKE ? OR content ILIKE ?" }.join(" AND ")
values = terms.flat_map { |t| [t, t] }
where(query, *values)
}
scope :search_advanced, ->(params) {
results = all
if params[:title].present?
results = results.where("title ILIKE ?", "%#{params[:title]}%")
end
if params[:author].present?
results = results.joins(:author).where("users.name ILIKE ?", "%#{params[:author]}%")
end
if params[:tags].present?
tag_names = params[:tags].split(',').map(&:strip)
results = results.joins(:tags).where(tags: { name: tag_names })
end
results.distinct
}
end
🎯 Expert-Level Questions (41-45)
💎 41. Rails Request Lifecycle and Internal Processing
Deep dive into how Rails processes requests from web server to response
Middleware stack visualization and custom middleware
Controller action execution order and benchmarking
# 1. Web Server receives request (Puma/Unicorn)
# 2. Rack middleware stack processes request
# 3. Rails Router matches the route
# 4. Controller instantiation and action execution
# 5. View rendering and response
# Detailed Request Flow:
class ApplicationController < ActionController::Base
around_action :log_request_lifecycle
private
def log_request_lifecycle
Rails.logger.info "1. Before controller action: #{controller_name}##{action_name}"
start_time = Time.current
yield # Execute the controller action
end_time = Time.current
Rails.logger.info "2. After controller action: #{(end_time - start_time) * 1000}ms"
end
end
# Middleware Stack Visualization
Rails.application.middleware.each_with_index do |middleware, index|
puts "#{index}: #{middleware.inspect}"
end
# Custom Middleware in the Stack
class RequestIdMiddleware
def initialize(app)
@app = app
end
def call(env)
env['HTTP_X_REQUEST_ID'] ||= SecureRandom.uuid
@app.call(env)
end
end
# Route Constraints and Processing
Rails.application.routes.draw do
# Routes are checked in order of definition
get '/posts/:id', to: 'posts#show', constraints: { id: /\d+/ }
get '/posts/:slug', to: 'posts#show_by_slug'
# Catch-all route (should be last)
match '*path', to: 'application#not_found', via: :all
end
# Controller Action Execution Order
class PostsController < ApplicationController
before_action :set_post, only: [:show, :edit, :update]
around_action :benchmark_action
after_action :log_user_activity
def show
# Main action logic
@related_posts = Post.where.not(id: @post.id).limit(5)
end
private
def benchmark_action
start_time = Time.current
yield
Rails.logger.info "Action took: #{Time.current - start_time}s"
end
end
# 1. Schema-based Multi-tenancy (Apartment gem)
# config/application.rb
require 'apartment'
Apartment.configure do |config|
config.excluded_models = ["User", "Tenant"]
config.tenant_names = lambda { Tenant.pluck(:subdomain) }
end
class ApplicationController < ActionController::Base
before_action :set_current_tenant
private
def set_current_tenant
subdomain = request.subdomain
tenant = Tenant.find_by(subdomain: subdomain)
if tenant
Apartment::Tenant.switch!(tenant.subdomain)
else
redirect_to root_url(subdomain: false)
end
end
end
# 2. Row-level Multi-tenancy (with default scopes)
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
belongs_to :tenant, optional: true
default_scope { where(tenant: Current.tenant) if Current.tenant }
def self.unscoped_for_tenant
unscoped.where(tenant: Current.tenant)
end
end
class Current < ActiveSupport::CurrentAttributes
attribute :tenant, :user
def tenant=(tenant)
super
Time.zone = tenant.time_zone if tenant&.time_zone
end
end
# 3. Hybrid Approach with Acts As Tenant
class User < ApplicationRecord
acts_as_tenant(:account)
validates :email, uniqueness: { scope: :account_id }
end
class Account < ApplicationRecord
has_many :users, dependent: :destroy
def switch_tenant!
ActsAsTenant.current_tenant = self
end
end
# 4. Database-level Multi-tenancy
class TenantMiddleware
def initialize(app)
@app = app
end
def call(env)
request = Rack::Request.new(env)
tenant_id = extract_tenant_id(request)
if tenant_id
ActiveRecord::Base.connection.execute(
"SET app.current_tenant_id = '#{tenant_id}'"
)
end
@app.call(env)
ensure
ActiveRecord::Base.connection.execute(
"SET app.current_tenant_id = ''"
)
end
private
def extract_tenant_id(request)
# Extract from subdomain, header, or JWT token
request.subdomain.presence ||
request.headers['X-Tenant-ID'] ||
decode_tenant_from_jwt(request.headers['Authorization'])
end
end
# 5. RLS (Row Level Security) in PostgreSQL
class AddRowLevelSecurity < ActiveRecord::Migration[7.0]
def up
# Enable RLS on posts table
execute "ALTER TABLE posts ENABLE ROW LEVEL SECURITY;"
# Create policy for tenant isolation
execute <<-SQL
CREATE POLICY tenant_isolation ON posts
USING (tenant_id = current_setting('app.current_tenant_id')::integer);
SQL
end
end
💎 43. Database Connection Pooling and Sharding
Connection pool configuration and monitoring Database connection pooling is a technique where a cache of database connections is maintained to be reused by applications, rather than creating a new connection for each database interaction. This improves performance and resource utilization by minimizing the overhead of establishing new connections with each query
Rails 6+ native sharding support
Custom sharding implementations Database sharding is a method of splitting a large database into smaller, faster, and more manageable pieces called “shards”. These shards are distributed across multiple database servers, enabling better performance and scalability for large datasets
Read/write splitting strategies
# 1. Connection Pool Configuration
# config/database.yml
production:
adapter: postgresql
host: <%= ENV['DB_HOST'] %>
database: myapp_production
username: <%= ENV['DB_USERNAME'] %>
password: <%= ENV['DB_PASSWORD'] %>
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 25 } %>
timeout: 5000
checkout_timeout: 5
reaping_frequency: 10
# Connection pool monitoring
class DatabaseConnectionPool
def self.status
ActiveRecord::Base.connection_pool.stat
end
# > ActiveRecord::Base.connection_pool.stat
# => {size: 5, connections: 0, busy: 0, dead: 0, idle: 0, waiting: 0, checkout_timeout: 5.0}
def self.with_connection_info
pool = ActiveRecord::Base.connection_pool
{
size: pool.size,
active_connections: pool.checked_out.size,
available_connections: pool.available.size,
slow_queries_count: Rails.cache.fetch('slow_queries_count', expires_in: 1.minute) { 0 }
}
end
end
# 2. Database Sharding (Rails 6+)
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
default: { writing: :primary, reading: :primary_replica },
shard_one: { writing: :primary_shard_one, reading: :primary_shard_one_replica }
}
end
class User < ApplicationRecord
# Shard by user ID
def self.shard_for(user_id)
user_id % 2 == 0 ? :default : :shard_one
end
def self.find_by_sharded_id(user_id)
shard = shard_for(user_id)
connected_to(shard: shard) { find(user_id) }
end
end
# 3. Custom Sharding Implementation
class ShardedModel < ApplicationRecord
self.abstract_class = true
class << self
def shard_for(key)
"shard_#{key.hash.abs % shard_count}"
end
def on_shard(shard_name)
establish_connection(database_config[shard_name])
yield
ensure
establish_connection(database_config['primary'])
end
def find_across_shards(id)
shard_count.times do |i|
shard_name = "shard_#{i}"
record = on_shard(shard_name) { find_by(id: id) }
return record if record
end
nil
end
private
def shard_count
Rails.application.config.shard_count || 4
end
def database_config
Rails.application.config.database_configuration[Rails.env]
end
end
end
# 4. Read/Write Splitting
class User < ApplicationRecord
# Automatic read/write splitting
connects_to database: { writing: :primary, reading: :replica }
def self.expensive_report
# Force read from replica
connected_to(role: :reading) do
select(:id, :name, :created_at)
.joins(:posts)
.group(:id)
.having('COUNT(posts.id) > ?', 10)
end
end
end
# Connection switching middleware
class DatabaseRoutingMiddleware
def initialize(app)
@app = app
end
def call(env)
request = Rack::Request.new(env)
# Use replica for GET requests
if request.get? && !admin_request?(request)
ActiveRecord::Base.connected_to(role: :reading) do
@app.call(env)
end
else
@app.call(env)
end
end
private
def admin_request?(request)
request.path.start_with?('/admin')
end
end
💎 44. Advanced Security Patterns and Best Practices
Content Security Policy (CSP) implementation
Rate limiting and DDoS protection
Secure headers and HSTS
Input sanitization and virus scanning
Enterprise-level security measures
# 1. Content Security Policy (CSP)
class ApplicationController < ActionController::Base
content_security_policy do |policy|
policy.default_src :self, :https
policy.font_src :self, :https, :data
policy.img_src :self, :https, :data
policy.object_src :none
policy.script_src :self, :https
policy.style_src :self, :https, :unsafe_inline
# Add nonce for inline scripts
policy.script_src :self, :https, :unsafe_eval if Rails.env.development?
end
content_security_policy_nonce_generator = -> request { SecureRandom.base64(16) }
content_security_policy_nonce_directives = %w(script-src)
end
# 2. Rate Limiting and DDoS Protection
class ApiController < ApplicationController
include ActionController::HttpAuthentication::Token::ControllerMethods
before_action :rate_limit_api_requests
before_action :authenticate_api_token
private
def rate_limit_api_requests
key = "api_rate_limit:#{request.remote_ip}"
count = Rails.cache.fetch(key, expires_in: 1.hour) { 0 }
if count >= 1000 # 1000 requests per hour
render json: { error: 'Rate limit exceeded' }, status: 429
return
end
Rails.cache.write(key, count + 1, expires_in: 1.hour)
end
def authenticate_api_token
authenticate_or_request_with_http_token do |token, options|
api_key = ApiKey.find_by(token: token)
api_key&.active? && !api_key.expired?
end
end
end
# 3. Secure Headers and HSTS
class ApplicationController < ActionController::Base
before_action :set_security_headers
private
def set_security_headers
response.headers['X-Frame-Options'] = 'DENY'
response.headers['X-Content-Type-Options'] = 'nosniff'
response.headers['X-XSS-Protection'] = '1; mode=block'
response.headers['Referrer-Policy'] = 'strict-origin-when-cross-origin'
if request.ssl?
response.headers['Strict-Transport-Security'] = 'max-age=31536000; includeSubDomains'
end
end
end
# 4. Input Sanitization and Validation
class UserInput
include ActiveModel::Model
include ActiveModel::Attributes
attribute :content, :string
attribute :email, :string
validates :content, presence: true, length: { maximum: 10000 }
validates :email, format: { with: URI::MailTo::EMAIL_REGEXP }
validate :no_malicious_content
validate :rate_limit_validation
private
def no_malicious_content
dangerous_patterns = [
/<script\b[^<]*(?:(?!<\/script>)<[^<]*)*<\/script>/mi,
/javascript:/i,
/vbscript:/i,
/onload\s*=/i,
/onerror\s*=/i
]
dangerous_patterns.each do |pattern|
if content&.match?(pattern)
errors.add(:content, 'contains potentially dangerous content')
break
end
end
end
def rate_limit_validation
# Implement user-specific validation rate limiting
key = "validation_attempts:#{email}"
attempts = Rails.cache.fetch(key, expires_in: 5.minutes) { 0 }
if attempts > 10
errors.add(:base, 'Too many validation attempts. Please try again later.')
else
Rails.cache.write(key, attempts + 1, expires_in: 5.minutes)
end
end
end
# 5. Secure File Upload with Virus Scanning
class Document < ApplicationRecord
has_one_attached :file
validate :acceptable_file
validate :virus_scan_clean
enum scan_status: { pending: 0, clean: 1, infected: 2 }
after_commit :scan_for_viruses, on: :create
private
def acceptable_file
return unless file.attached?
# Check file size
unless file.blob.byte_size <= 10.megabytes
errors.add(:file, 'is too large')
end
# Check file type
allowed_types = %w[application/pdf image/jpeg image/png text/plain]
unless allowed_types.include?(file.blob.content_type)
errors.add(:file, 'type is not allowed')
end
# Check filename for path traversal
if file.filename.to_s.include?('..')
errors.add(:file, 'filename is invalid')
end
end
def virus_scan_clean
return unless file.attached? && scan_status == 'infected'
errors.add(:file, 'failed virus scan')
end
def scan_for_viruses
VirusScanJob.perform_later(self)
end
end
class VirusScanJob < ApplicationJob
def perform(document)
# Use ClamAV or similar service
result = system("clamscan --no-summary #{document.file.blob.service.path_for(document.file.blob.key)}")
if $?.success?
document.update!(scan_status: :clean)
else
document.update!(scan_status: :infected)
document.file.purge # Remove infected file
end
end
end
💎 45. Application Performance Monitoring (APM) and Observability
Custom metrics and instrumentation
Database query analysis and slow query detection
Background job monitoring
Health check endpoints
Real-time performance dashboards
# 1. Custom Metrics and Instrumentation
class ApplicationController < ActionController::Base
include MetricsCollector
around_action :collect_performance_metrics
after_action :track_user_behavior
private
def collect_performance_metrics
start_time = Time.current
start_memory = memory_usage
yield
end_time = Time.current
end_memory = memory_usage
MetricsCollector.record_request(
controller: controller_name,
action: action_name,
duration: (end_time - start_time) * 1000,
memory_delta: end_memory - start_memory,
status: response.status,
user_agent: request.user_agent
)
end
def memory_usage
`ps -o rss= -p #{Process.pid}`.to_i
end
end
module MetricsCollector
extend self
def record_request(metrics)
# Send to APM service (New Relic, Datadog, etc.)
Rails.logger.info("METRICS: #{metrics.to_json}")
# Custom metrics for business logic
if metrics[:controller] == 'orders' && metrics[:action] == 'create'
increment_counter('orders.created')
record_gauge('orders.creation_time', metrics[:duration])
end
# Performance alerts
if metrics[:duration] > 1000 # > 1 second
SlowRequestNotifier.notify(metrics)
end
end
def increment_counter(metric_name, tags = {})
StatsD.increment(metric_name, tags: tags)
end
def record_gauge(metric_name, value, tags = {})
StatsD.gauge(metric_name, value, tags: tags)
end
end
# 2. Database Query Analysis
class QueryAnalyzer
def self.analyze_slow_queries
ActiveSupport::Notifications.subscribe('sql.active_record') do |name, start, finish, id, payload|
duration = (finish - start) * 1000
if duration > 100 # queries taking more than 100ms
Rails.logger.warn({
event: 'slow_query',
duration: duration,
sql: payload[:sql],
binds: payload[:binds]&.map(&:value),
name: payload[:name],
connection_id: payload[:connection_id]
}.to_json)
# Send to APM
NewRelic::Agent.record_metric('Database/SlowQuery', duration)
end
end
end
end
# 3. Background Job Monitoring
class MonitoredJob < ApplicationJob
around_perform :monitor_job_performance
retry_on StandardError, wait: 5.seconds, attempts: 3
private
def monitor_job_performance
start_time = Time.current
job_name = self.class.name
begin
yield
# Record successful job metrics
duration = Time.current - start_time
MetricsCollector.record_gauge("jobs.#{job_name.underscore}.duration", duration * 1000)
MetricsCollector.increment_counter("jobs.#{job_name.underscore}.success")
rescue => error
# Record failed job metrics
MetricsCollector.increment_counter("jobs.#{job_name.underscore}.failure")
# Enhanced error tracking
ErrorTracker.capture_exception(error, {
job_class: job_name,
job_id: job_id,
queue_name: queue_name,
arguments: arguments,
executions: executions
})
raise
end
end
end
# 4. Health Check Endpoints
class HealthController < ApplicationController
skip_before_action :authenticate_user!
def check
render json: { status: 'ok', timestamp: Time.current.iso8601 }
end
def detailed
checks = {
database: database_check,
redis: redis_check,
storage: storage_check,
jobs: job_queue_check
}
overall_status = checks.values.all? { |check| check[:status] == 'ok' }
status_code = overall_status ? 200 : 503
render json: {
status: overall_status ? 'ok' : 'error',
checks: checks,
timestamp: Time.current.iso8601
}, status: status_code
end
private
def database_check
ActiveRecord::Base.connection.execute('SELECT 1')
{ status: 'ok', response_time: measure_time { ActiveRecord::Base.connection.execute('SELECT 1') } }
rescue => e
{ status: 'error', error: e.message }
end
def redis_check
Redis.current.ping
{ status: 'ok', response_time: measure_time { Redis.current.ping } }
rescue => e
{ status: 'error', error: e.message }
end
def measure_time
start_time = Time.current
yield
((Time.current - start_time) * 1000).round(2)
end
end
# 5. Real-time Performance Dashboard
class PerformanceDashboard
include ActionView::Helpers::NumberHelper
def self.current_stats
{
requests_per_minute: request_rate,
average_response_time: average_response_time,
error_rate: error_rate,
active_users: active_user_count,
database_stats: database_performance,
background_jobs: job_queue_stats
}
end
def self.request_rate
# Calculate from metrics store
Rails.cache.fetch('metrics:requests_per_minute', expires_in: 30.seconds) do
# Implementation depends on your metrics store
StatsD.get_rate('requests.total')
end
end
def self.database_performance
pool = ActiveRecord::Base.connection_pool
{
pool_size: pool.size,
active_connections: pool.checked_out.size,
available_connections: pool.available.size,
slow_queries_count: Rails.cache.fetch('slow_queries_count', expires_in: 1.minute) { 0 }
}
end
def self.job_queue_stats
if defined?(Sidekiq)
stats = Sidekiq::Stats.new
{
processed: stats.processed,
failed: stats.failed,
enqueued: stats.enqueued,
retry_size: stats.retry_size
}
else
{ message: 'Background job system not available' }
end
end
end
These additional 5 questions focus on enterprise-level concerns that senior Rails developers encounter in production environments, making this the most comprehensive Rails guide available with real-world, production-tested examples.
🎯 New Areas Added (Questions 46-50):
💎 46. 📧 ActionMailer and Email Handling
Email configuration and delivery methods
Email templates (HTML + Text)
Background email processing
Email testing and previews
Email analytics and interceptors
# 1. Basic Mailer Setup
class UserMailer < ApplicationMailer
default from: 'noreply@example.com'
def welcome_email(user)
@user = user
@url = login_url
mail(
to: @user.email,
subject: 'Welcome to Our Platform!',
template_path: 'mailers/user_mailer',
template_name: 'welcome'
)
end
def password_reset(user, token)
@user = user
@token = token
@reset_url = edit_password_reset_url(token: @token)
mail(
to: @user.email,
subject: 'Password Reset Instructions',
reply_to: 'support@example.com'
)
end
def order_confirmation(order)
@order = order
@user = order.user
# Attach invoice PDF
attachments['invoice.pdf'] = order.generate_invoice_pdf
# Inline images
attachments.inline['logo.png'] = File.read(Rails.root.join('app/assets/images/logo.png'))
mail(
to: @user.email,
subject: "Order Confirmation ##{@order.id}",
delivery_method_options: { user_name: ENV['SMTP_USERNAME'] }
)
end
end
# 2. Email Templates (HTML + Text)
# app/views/user_mailer/welcome_email.html.erb
<%= content_for :title, "Welcome #{@user.name}!" %>
<div class="email-container">
<h1>Welcome to Our Platform!</h1>
<p>Hi <%= @user.name %>,</p>
<p>Thank you for joining us. Click the link below to get started:</p>
<p><%= link_to "Get Started", @url, class: "button" %></p>
</div>
# app/views/user_mailer/welcome_email.text.erb
Welcome <%= @user.name %>!
Thank you for joining our platform.
Get started: <%= @url %>
# 3. Email Configuration
# config/environments/production.rb
config.action_mailer.delivery_method = :smtp
config.action_mailer.smtp_settings = {
address: ENV['SMTP_SERVER'],
port: 587,
domain: ENV['DOMAIN'],
user_name: ENV['SMTP_USERNAME'],
password: ENV['SMTP_PASSWORD'],
authentication: 'plain',
enable_starttls_auto: true,
open_timeout: 5,
read_timeout: 5
}
# For SendGrid
config.action_mailer.smtp_settings = {
address: 'smtp.sendgrid.net',
port: 587,
authentication: :plain,
user_name: 'apikey',
password: ENV['SENDGRID_API_KEY']
}
# 4. Background Email Processing
class UserRegistrationService
def call
user = create_user
# Send immediately
UserMailer.welcome_email(user).deliver_now
# Send in background (recommended)
UserMailer.welcome_email(user).deliver_later
# Send at specific time
UserMailer.welcome_email(user).deliver_later(wait: 1.hour)
user
end
end
# 5. Email Testing and Previews
# test/mailers/user_mailer_test.rb
class UserMailerTest < ActionMailer::TestCase
test "welcome email" do
user = users(:john)
email = UserMailer.welcome_email(user)
assert_emails 1 do
email.deliver_now
end
assert_equal ['noreply@example.com'], email.from
assert_equal [user.email], email.to
assert_equal 'Welcome to Our Platform!', email.subject
assert_match 'Hi John', email.body.to_s
end
end
# Email Previews for development
# test/mailers/previews/user_mailer_preview.rb
class UserMailerPreview < ActionMailer::Preview
def welcome_email
UserMailer.welcome_email(User.first)
end
def password_reset
user = User.first
token = "sample-token-123"
UserMailer.password_reset(user, token)
end
end
# 6. Email Analytics and Tracking
class TrackableMailer < ApplicationMailer
after_action :track_email_sent
private
def track_email_sent
EmailAnalytics.track_sent(
mailer: self.class.name,
action: action_name,
recipient: message.to.first,
subject: message.subject,
sent_at: Time.current
)
end
end
# 7. Email Interceptors
class EmailInterceptor
def self.delivering_email(message)
# Prevent emails in staging
if Rails.env.staging?
message.to = ['staging@example.com']
message.cc = nil
message.bcc = nil
message.subject = "[STAGING] #{message.subject}"
end
# Add environment prefix
unless Rails.env.production?
message.subject = "[#{Rails.env.upcase}] #{message.subject}"
end
end
end
# Register interceptor
ActionMailer::Base.register_interceptor(EmailInterceptor)
💎 47. 🌍 Internationalization (I18n)
Multi-language application setup
Locale management and routing
Translation files and fallbacks
Model translations with Globalize
Date/time localization
# 1. Basic I18n Configuration
# config/application.rb
config.i18n.load_path += Dir[Rails.root.join('config', 'locales', '**', '*.{rb,yml}')]
config.i18n.available_locales = [:en, :es, :fr, :de, :ja]
config.i18n.default_locale = :en
config.i18n.fallbacks = true
# 2. Locale Files Structure
# config/locales/en.yml
en:
hello: "Hello"
welcome:
message: "Welcome %{name}!"
title: "Welcome to Our Site"
activerecord:
models:
user: "User"
post: "Post"
attributes:
user:
name: "Full Name"
email: "Email Address"
post:
title: "Title"
content: "Content"
errors:
models:
user:
attributes:
email:
taken: "Email address is already in use"
invalid: "Please enter a valid email address"
date:
formats:
default: "%Y-%m-%d"
short: "%b %d"
long: "%B %d, %Y"
time:
formats:
default: "%a, %d %b %Y %H:%M:%S %z"
short: "%d %b %H:%M"
long: "%B %d, %Y %H:%M"
# config/locales/es.yml
es:
hello: "Hola"
welcome:
message: "¡Bienvenido %{name}!"
title: "Bienvenido a Nuestro Sitio"
activerecord:
models:
user: "Usuario"
post: "Publicación"
# 3. Controller Locale Handling
class ApplicationController < ActionController::Base
before_action :set_locale
private
def set_locale
I18n.locale = locale_from_params ||
locale_from_user ||
locale_from_header ||
I18n.default_locale
end
def locale_from_params
return unless params[:locale]
return unless I18n.available_locales.include?(params[:locale].to_sym)
params[:locale]
end
def locale_from_user
current_user&.locale if user_signed_in?
end
def locale_from_header
request.env['HTTP_ACCEPT_LANGUAGE']&.scan(/^[a-z]{2}/)&.first
end
# URL generation with locale
def default_url_options
{ locale: I18n.locale }
end
end
# 4. Routes with Locale
# config/routes.rb
Rails.application.routes.draw do
scope "(:locale)", locale: /#{I18n.available_locales.join("|")}/ do
root 'home#index'
resources :posts
resources :users
end
# Redirect root to default locale
root to: redirect("/#{I18n.default_locale}", status: 302)
end
# 5. View Translations
# app/views/posts/index.html.erb
<h1><%= t('posts.index.title') %></h1>
<p><%= t('posts.index.description', count: @posts.count) %></p>
<%= link_to t('posts.new'), new_post_path, class: 'btn btn-primary' %>
<% @posts.each do |post| %>
<div class="post">
<h3><%= post.title %></h3>
<p><%= t('posts.published_at', date: l(post.created_at, format: :short)) %></p>
<p><%= truncate(post.content, length: 150) %></p>
</div>
<% end %>
# 6. Model Translations (with Globalize gem)
class Post < ApplicationRecord
translates :title, :content
validates :title, presence: true
validates :content, presence: true
end
# Usage
post = Post.create(
title: "English Title",
content: "English content"
)
I18n.with_locale(:es) do
post.update(
title: "Título en Español",
content: "Contenido en español"
)
end
# Access translations
I18n.locale = :en
post.title # => "English Title"
I18n.locale = :es
post.title # => "Título en Español"
# 7. Form Helpers with I18n
<%= form_with model: @user do |f| %>
<div class="field">
<%= f.label :name, t('activerecord.attributes.user.name') %>
<%= f.text_field :name %>
</div>
<div class="field">
<%= f.label :email %>
<%= f.email_field :email %>
</div>
<%= f.submit t('helpers.submit.user.create') %>
<% end %>
# 8. Pluralization
# config/locales/en.yml
en:
posts:
count:
zero: "No posts"
one: "1 post"
other: "%{count} posts"
# Usage in views
<%= t('posts.count', count: @posts.count) %>
# 9. Date and Time Localization
# Helper method
module ApplicationHelper
def localized_date(date, format = :default)
l(date, format: format) if date
end
def relative_time(time)
time_ago_in_words(time, locale: I18n.locale)
end
end
# Usage
<%= localized_date(@post.created_at, :long) %>
<%= relative_time(@post.created_at) %>
# 10. Locale Switching
# Helper for locale switcher
module ApplicationHelper
def locale_switcher
content_tag :div, class: 'locale-switcher' do
I18n.available_locales.map do |locale|
link_to_unless I18n.locale == locale,
locale.upcase,
url_for(locale: locale),
class: ('active' if I18n.locale == locale)
end.join(' | ').html_safe
end
end
end
💎 48. 🔧 Error Handling and Logging
Global exception handling strategies
Structured logging patterns
Custom error classes and business logic errors
API error responses
Production error tracking
# 1. Global Exception Handling
class ApplicationController < ActionController::Base
rescue_from StandardError, with: :handle_standard_error
rescue_from ActiveRecord::RecordNotFound, with: :handle_not_found
rescue_from ActionController::ParameterMissing, with: :handle_bad_request
rescue_from Pundit::NotAuthorizedError, with: :handle_unauthorized
private
def handle_standard_error(exception)
ErrorLogger.capture_exception(exception, {
user_id: current_user&.id,
request_id: request.uuid,
url: request.url,
params: params.to_unsafe_h,
user_agent: request.user_agent
})
if Rails.env.development?
raise exception
else
render_error_page(500, 'Something went wrong')
end
end
def handle_not_found(exception)
ErrorLogger.capture_exception(exception, { level: 'info' })
render_error_page(404, 'Page not found')
end
def handle_bad_request(exception)
ErrorLogger.capture_exception(exception, { level: 'warning' })
render_error_page(400, 'Bad request')
end
def handle_unauthorized(exception)
ErrorLogger.capture_exception(exception, { level: 'warning' })
if user_signed_in?
render_error_page(403, 'Access denied')
else
redirect_to login_path, alert: 'Please log in to continue'
end
end
def render_error_page(status, message)
respond_to do |format|
format.html { render 'errors/error', locals: { message: message }, status: status }
format.json { render json: { error: message }, status: status }
end
end
end
# 2. Structured Logging
class ApplicationController < ActionController::Base
around_action :log_request_details
private
def log_request_details
start_time = Time.current
Rails.logger.info({
event: 'request_started',
request_id: request.uuid,
method: request.method,
path: request.path,
remote_ip: request.remote_ip,
user_agent: request.user_agent,
user_id: current_user&.id,
timestamp: start_time.iso8601
}.to_json)
begin
yield
ensure
duration = Time.current - start_time
Rails.logger.info({
event: 'request_completed',
request_id: request.uuid,
status: response.status,
duration_ms: (duration * 1000).round(2),
timestamp: Time.current.iso8601
}.to_json)
end
end
end
# 3. Custom Error Logger
class ErrorLogger
class << self
def capture_exception(exception, context = {})
error_data = {
exception_class: exception.class.name,
message: exception.message,
backtrace: exception.backtrace&.first(10),
context: context,
timestamp: Time.current.iso8601,
environment: Rails.env,
server: Socket.gethostname
}
# Log to Rails logger
Rails.logger.error(error_data.to_json)
# Send to external service (Sentry, Bugsnag, etc.)
if Rails.env.production?
Sentry.capture_exception(exception, extra: context)
end
# Store in database for analysis
ErrorReport.create!(
exception_class: exception.class.name,
message: exception.message,
backtrace: exception.backtrace.join("\n"),
context: context,
occurred_at: Time.current
)
end
def capture_message(message, level: 'info', context: {})
log_data = {
event: 'custom_log',
level: level,
message: message,
context: context,
timestamp: Time.current.iso8601
}
case level
when 'error'
Rails.logger.error(log_data.to_json)
when 'warning'
Rails.logger.warn(log_data.to_json)
else
Rails.logger.info(log_data.to_json)
end
end
end
end
# 4. Business Logic Error Handling
class OrderProcessingService
include ActiveModel::Model
class OrderProcessingError < StandardError; end
class PaymentError < OrderProcessingError; end
class InventoryError < OrderProcessingError; end
def call(order)
ActiveRecord::Base.transaction do
validate_inventory!(order)
process_payment!(order)
update_inventory!(order)
send_confirmation!(order)
order.update!(status: 'completed')
rescue PaymentError => e
order.update!(status: 'payment_failed', error_message: e.message)
ErrorLogger.capture_exception(e, { order_id: order.id, service: 'payment' })
false
rescue InventoryError => e
order.update!(status: 'inventory_failed', error_message: e.message)
ErrorLogger.capture_exception(e, { order_id: order.id, service: 'inventory' })
false
rescue => e
order.update!(status: 'failed', error_message: e.message)
ErrorLogger.capture_exception(e, { order_id: order.id, service: 'order_processing' })
false
end
end
private
def validate_inventory!(order)
order.line_items.each do |item|
unless item.product.sufficient_stock?(item.quantity)
raise InventoryError, "Insufficient stock for #{item.product.name}"
end
end
end
def process_payment!(order)
result = PaymentService.charge(order.total, order.payment_method)
raise PaymentError, result.error_message unless result.success?
end
end
# 5. Background Job Error Handling
class ProcessOrderJob < ApplicationJob
queue_as :default
retry_on StandardError, wait: 5.seconds, attempts: 3
retry_on PaymentService::TemporaryError, wait: 30.seconds, attempts: 5
discard_on ActiveJob::DeserializationError
def perform(order_id)
order = Order.find(order_id)
unless OrderProcessingService.new.call(order)
ErrorLogger.capture_message(
"Order processing failed for order #{order_id}",
level: 'error',
context: { order_id: order_id, attempt: executions }
)
end
rescue ActiveRecord::RecordNotFound => e
ErrorLogger.capture_exception(e, {
order_id: order_id,
message: "Order not found during processing"
})
# Don't retry for missing records
rescue => e
ErrorLogger.capture_exception(e, {
order_id: order_id,
job_id: job_id,
executions: executions
})
# Re-raise to trigger retry mechanism
raise
end
end
# 6. API Error Responses
module ApiErrorHandler
extend ActiveSupport::Concern
included do
rescue_from StandardError, with: :handle_api_error
rescue_from ActiveRecord::RecordNotFound, with: :handle_not_found
rescue_from ActiveRecord::RecordInvalid, with: :handle_validation_error
end
private
def handle_api_error(exception)
ErrorLogger.capture_exception(exception)
render json: {
error: {
type: 'internal_error',
message: 'An unexpected error occurred',
request_id: request.uuid
}
}, status: 500
end
def handle_not_found(exception)
render json: {
error: {
type: 'not_found',
message: 'Resource not found'
}
}, status: 404
end
def handle_validation_error(exception)
render json: {
error: {
type: 'validation_error',
message: 'Validation failed',
details: exception.record.errors.full_messages
}
}, status: 422
end
end
# 7. Custom Error Pages
# app/views/errors/error.html.erb
<div class="error-page">
<h1><%= message %></h1>
<p>We're sorry, but something went wrong.</p>
<% if Rails.env.development? %>
<div class="debug-info">
<h3>Debug Information</h3>
<p>Request ID: <%= request.uuid %></p>
<p>Time: <%= Time.current %></p>
</div>
<% end %>
<%= link_to "Go Home", root_path, class: "btn btn-primary" %>
</div>
💎 49. ⚙️ Rails Configuration and Environment Management
Whether you’re preparing for a Rails interview or looking to level up your Rails expertise, this guide covers everything from fundamental concepts to advanced architectural patterns, deployment strategies, and production concerns that senior Rails developers encounter in enterprise environments.
Background job processing is a cornerstone of modern web applications, and in the Ruby ecosystem, one library has dominated this space for over a decade: Sidekiq. Whether you’re building a simple Rails app or a complex distributed system, chances are you’ve encountered or will encounter Sidekiq. But how does it actually work under the hood, and why has it remained the go-to choice for Ruby developers?
🔍 What is Sidekiq?
Sidekiq is a Ruby background job processor that allows you to offload time-consuming tasks from your web application’s request-response cycle. Instead of making users wait for slow operations like sending emails, processing images, or calling external APIs, you can queue these tasks to be executed asynchronously in the background.
# Instead of this blocking the web request
UserMailer.welcome_email(user).deliver_now
# You can do this
UserMailer.welcome_email(user).deliver_later
❤️ Why Ruby Developers Love Sidekiq
⚡ Battle-Tested Reliability
With over 10 years in production and widespread adoption across the Ruby community, Sidekiq has proven its reliability in handling millions of jobs across thousands of applications.
🧵 Efficient Threading Model
Unlike many other Ruby job processors that use a forking model, Sidekiq uses threads. This makes it incredibly memory-efficient since threads share the same memory space, allowing you to process multiple jobs concurrently with minimal memory overhead.
🚄 Redis-Powered Performance
Sidekiq leverages Redis’s lightning-fast data structures, using simple list operations (BRPOP, LPUSH) that provide constant-time complexity for job queuing and dequeuing.
🔧 Simple Integration
For Rails applications, integration is often as simple as adding the gem and configuring a few settings. Sidekiq works seamlessly with ActiveJob, Rails’ job interface.
🌐 Rich Ecosystem
The library comes with a web UI for monitoring jobs, extensive configuration options, and a thriving ecosystem of plugins and extensions.
🔄 Alternatives to Sidekiq
While Sidekiq dominates the Ruby job processing landscape, several alternatives exist:
Resque: The original Redis-backed job processor for Ruby, uses a forking model
DelayedJob: Database-backed job processor, simpler but less performant
Que: PostgreSQL-based job processor using advisory locks
GoodJob: Rails-native job processor that stores jobs in PostgreSQL
Job Enqueueing: Jobs are pushed to Redis lists using LPUSH
Job Fetching: Worker processes use BRPOP to atomically fetch jobs
Execution: Each job runs in its own thread within a processor
Completion: Successful jobs are simply removed; failed jobs enter retry logic
✨ The Threading Magic
Here’s the fascinating part: Sidekiq uses a Manager class that spawns multiple Processor threads:
# Conceptual representation
@workers = @concurrency.times.map do
Processor.new(self, &method(:processor_died))
end
Each processor thread runs an infinite loop, constantly fetching and executing jobs:
def start
@thread = safe_thread("processor", &method(:run))
end
private
def run
while !@done
process_one
end
rescue Sidekiq::Shutdown
# Graceful shutdown
end
🧵 Ruby’s Threading Reality: Debunking the Myth
There’s a common misconception that “Ruby doesn’t support threads.” This isn’t accurate. Ruby absolutely supports threads, but it has an important limitation called the Global Interpreter Lock (GIL).
🔒 What the GIL Means:
Only one Ruby thread can execute Ruby code at a time
I/O operations release the GIL, allowing other threads to run
Most background jobs involve I/O: database queries, API calls, file operations
This makes Sidekiq’s threading model perfect for typical background jobs:
# This job releases the GIL during I/O operations
class EmailJob < ApplicationJob
def perform(user_id)
user = User.find(user_id) # Database I/O - GIL released
email_service.send_email(user) # HTTP request - GIL released
log_event(user) # File/DB I/O - GIL released
end
end
Multiple EmailJob instances can run concurrently because they spend most of their time in I/O operations where the GIL is released.
🗄️ Is Redis Mandatory?
Yes, Redis is absolutely mandatory for Sidekiq. Redis serves as:
Job Storage: All job data is stored in Redis lists and sorted sets
Queue Management: Different queues are implemented as separate Redis lists
Scheduling: Future and retry jobs use Redis sorted sets with timestamps
Statistics: Job metrics and monitoring data live in Redis
The tight Redis integration is actually one of Sidekiq’s strengths:
# config/initializers/sidekiq.rb
Sidekiq.configure_server do |config|
config.redis = { url: ENV['REDIS_URL'] }
config.concurrency = 5
end
Sidekiq.configure_client do |config|
config.redis = { url: ENV['REDIS_URL'] }
end
💼 3. Creating Jobs
# app/jobs/user_onboarding_job.rb
class UserOnboardingJob < ApplicationJob
queue_as :default
def perform(user_id)
user = User.find(user_id)
UserMailer.welcome_email(user).deliver_now
user.update!(onboarded_at: Time.current)
end
end
# Enqueue the job
UserOnboardingJob.perform_later(user.id)
🎯 4. Advanced Features
# Scheduled jobs
UserOnboardingJob.set(wait: 1.hour).perform_later(user.id)
# Job priorities with different queues
class UrgentJob < ApplicationJob
queue_as :high_priority
end
# Sidekiq configuration for queue priorities
# config/sidekiq.yml
:queues:
- [high_priority, 3]
- [default, 2]
- [low_priority, 1]
📊 5. Monitoring and Debugging
Sidekiq provides a fantastic web UI accessible via:
# config/routes.rb
require 'sidekiq/web'
mount Sidekiq::Web => '/sidekiq'
🏭 Production Considerations
🛑 Graceful Shutdown
Sidekiq handles graceful shutdowns elegantly. When receiving SIGTERM (common in Kubernetes deployments):
Stops accepting new jobs
Allows current jobs to complete (with timeout)
Requeues any unfinished jobs back to Redis
Shuts down cleanly
⚠️ Job Loss Scenarios
While Sidekiq provides “at least once” delivery semantics, jobs can be lost in extreme scenarios:
Process killed with SIGKILL (no graceful shutdown)
Redis memory exhaustion during job requeuing
Redis server failures with certain persistence configurations
For mission-critical jobs, consider:
Implementing idempotency
Adding liveness checks via cron jobs
Using Sidekiq Pro for guaranteed job delivery
🎯 Conclusion
Sidekiq remains the gold standard for background job processing in Ruby applications. Its efficient threading model, Redis-powered performance, and seamless Rails integration make it an excellent choice for modern applications. The library’s maturity doesn’t mean stagnation – it represents battle-tested reliability with continuous evolution.
Whether you’re building a simple Rails 8 application or a complex distributed system, Sidekiq provides the robust foundation you need for handling background work efficiently and reliably.
No, Sidekiq is actually quite lightweight! Here’s why:
Memory Efficiency: Sidekiq uses a threading model instead of forking processes. This is crucial because:
Threads share the same memory space
Multiple jobs can run concurrently with minimal memory overhead
Much more memory-efficient than alternatives like Resque that fork processes
Performance: The blog post mentions that Sidekiq leverages Redis’s lightning-fast operations using simple list operations (BRPOP, LPUSH) with constant-time complexity.
Resource Usage: The default concurrency is typically set to RAILS_MAX_THREADS (usually 5), meaning you get good parallelism without overwhelming your system.
2. Sidekiq vs ActiveJob Relationship
Sidekiq is NOT an alternative to ActiveJob – they work together beautifully:
ActiveJob is Rails’ interface/abstraction layer for background jobs. It provides:
A common API for defining jobs
Queue adapters for different backends
Built-in features like retries, scheduling, etc.
Sidekiq is a queue adapter/backend that actually processes the jobs. The relationship works like this:
# ActiveJob provides the interface
class UserOnboardingJob < ApplicationJob
queue_as :default
def perform(user_id)
# Your job logic here
end
end
# Sidekiq acts as the backend processor
# config/application.rb
config.active_job.queue_adapter = :sidekiq
Think of it this way:
ActiveJob = The standardized job interface (like ActiveRecord for databases)
Sidekiq = The actual job processing engine (like PostgreSQL for databases)
When you write UserOnboardingJob.perform_later(user.id), ActiveJob translates this into Sidekiq’s format and queues it in Redis, then Sidekiq processes it.
Other queue adapters you could use with ActiveJob include:
:delayed_job
:resque
:solid_queue (Rails 8’s new default)
:que
But Sidekiq remains the most popular choice due to its performance and reliability!
🎯 Why Solid Queue (Rails 8) Was Created
1. Zero External Dependencies
Sidekiq requires Redis, which means:
Additional infrastructure to set up and maintain
Extra cost on hosting platforms (Heroku Redis add-on costs money)
More complexity in deployment and monitoring
Solid Queue uses your existing PostgreSQL database, so:
No additional infrastructure needed
Every Rails app already has a database
Simpler deployment and maintenance
2. Rails-Native Philosophy
The Rails team wanted a solution that’s:
Built specifically for Rails by the Rails team
Follows Rails conventions and patterns
Integrates seamlessly without external dependencies
Ships “out of the box” with Rails
3. Simplicity for Smaller Apps
For many Rails applications:
Setting up Redis just for background jobs is overkill
The job volume doesn’t require Redis-level performance
Database-backed jobs are perfectly sufficient
4. Cost and Hosting Considerations
Heroku: Adding Redis costs $5-15+ per month extra
Smaller projects: May not justify the additional infrastructure cost
Development: Easier local development without Redis setup
Simpler backup/restore (part of your database backup)
🤔 When to Choose Which?
Choose Solid Queue when:
Building smaller to medium Rails apps
Want to minimize infrastructure complexity
Don’t need extremely high job throughput
Cost is a consideration
Want Rails-native solution
Choose Sidekiq when:
High job volume/throughput requirements
Already using Redis in your stack
Need advanced features (Sidekiq Pro/Enterprise)
Want the most battle-tested solution
Performance is critical
📊 Real-World Impact
# Solid Queue - No Redis needed
# Uses your existing PostgreSQL database
config.active_job.queue_adapter = :solid_queue
# Sidekiq - Requires Redis
# But offers superior performance
config.active_job.queue_adapter = :sidekiq
🎯 The Bottom Line
Solid Queue wasn’t created because Sidekiq is bad – it’s created because:
Different use cases: Not every app needs Redis-level performance
Rails philosophy: “Convention over configuration” includes sensible defaults
Accessibility: Lower barrier to entry for new Rails developers
Infrastructure simplicity: One less moving part to manage
Sidekiq remains excellent and is still widely used in production. Many companies will continue using Sidekiq, especially for high-traffic applications.
Think of it like this:
Solid Queue = The sensible, zero-dependency default (like SQLite for development)
Sidekiq = The high-performance, battle-tested option (like PostgreSQL for production)
Both have their place in the ecosystem! The Rails team just wanted to provide a great default option that doesn’t require additional infrastructure setup.
🚀 What Happens When You Run bin/sidekiq
1. Command Execution
$ bin/sidekiq
This executes the Sidekiq binary, which typically looks like this:
#!/usr/bin/env ruby
# bin/sidekiq (simplified)
require 'sidekiq/cli'
cli = Sidekiq::CLI.new
cli.parse # Parse command line arguments
cli.run # Start the main process
2. CLI Initialization Process
When Sidekiq::CLI.new is created, here’s what happens:
class Sidekiq::CLI
def initialize
# Set up signal handlers
setup_signals
# Parse configuration
@config = Sidekiq::Config.new
end
def run
# 1. Load Rails application
load_application
# 2. Setup Redis connection
setup_redis
# 3. Create the Manager (this is key!)
@manager = Sidekiq::Manager.new(@config)
# 4. Start the manager
@manager.start
# 5. Enter the main loop (THIS IS WHY IT DOESN'T EXIT!)
wait_for_shutdown
end
end
🔄 The Continuous Loop Architecture
Yes, it’s multiple loops! Here’s the hierarchy:
Main Process Loop
def wait_for_shutdown
while !@done
# Wait for shutdown signal (SIGTERM, SIGINT, etc.)
sleep(SCAN_INTERVAL)
# Check if we should gracefully shutdown
check_shutdown_conditions
end
end
Manager Loop
The Manager spawns and manages worker threads:
class Sidekiq::Manager
def start
# Spawn processor threads
@workers = @concurrency.times.map do |i|
Processor.new(self, &method(:processor_died))
end
# Start each processor thread
@workers.each(&:start)
# Start the poller thread (for scheduled jobs)
@poller.start if @poller
end
end
Processor Thread Loops (The Real Workers)
Each processor thread runs this loop:
class Sidekiq::Processor
def run
while !@done
process_one_job
end
rescue Sidekiq::Shutdown
# Graceful shutdown
end
private
def process_one_job
# 1. FETCH: Block and wait for a job from Redis
job = fetch_job_from_redis # This is where it "listens"
# 2. PROCESS: Execute the job
process_job(job) if job
# 3. LOOP: Go back and wait for next job
end
end
🎧 How It “Listens” for Jobs
The key is the Redis BRPOP command:
def fetch_job_from_redis
# BRPOP = "Blocking Right Pop"
# This blocks until a job is available!
redis.brpop("queue:default", "queue:low", timeout: 2)
end
What BRPOP does:
Blocks the thread until a job appears in any of the specified queues
Times out after 2 seconds and checks again
Immediately returns when a new job is pushed to the queue
# Thread 1, 2, 3, 4, 5 each run:
loop do
job = redis.brpop("queue:default", timeout: 2)
if job
execute_job(job)
end
# Continue looping...
end
3. When You Queue a Job
# In your Rails app:
UserMailer.welcome_email(user).deliver_later
# This does:
redis.lpush("queue:default", job_data.to_json)
4. Immediate Response
One of the blocking BRPOP calls immediately receives the job
That thread processes the job
Goes back to listening for the next job
The process stays running because:
Main thread sleeps and waits for shutdown signals
Worker threads continuously loop, blocking on Redis
No natural exit condition – it’s designed to run indefinitely
Only exits when receiving termination signals (SIGTERM, SIGINT)
📊 Visual Representation
Main Process
├── Manager Thread
├── Processor Thread 1 ──┐
├── Processor Thread 2 ──┼─── All blocking on redis.brpop()
├── Processor Thread 3 ──┼─── Waiting for jobs...
├── Processor Thread 4 ──┼─── Ready to process immediately
└── Processor Thread 5 ──┘
Redis Queue: [job1, job2, job3] ──→ BRPOP ──→ Process job
1. 🛌 What Does sleep Do in Ruby?
Yes, sleep pauses execution for the given number of seconds:
sleep(5) # Pauses for 5 seconds
sleep(0.5) # Pauses for 500 milliseconds
sleep(1.5) # Pauses for 1.5 seconds
Why the while Loop is Needed
The code:
while !@done
# Wait for shutdown signal (SIGTERM, SIGINT, etc.)
sleep(SCAN_INTERVAL)
end
Without the loop, the process would:
sleep(SCAN_INTERVAL) # Sleep once for ~2 seconds
# Then exit! 😱
With the loop, it does this:
# Loop 1: Check if @done=false → sleep 2 seconds
# Loop 2: Check if @done=false → sleep 2 seconds
# Loop 3: Check if @done=false → sleep 2 seconds
# ...continues forever until @done=true
Why This Pattern?
The main thread needs to:
Stay alive to keep the process running
Periodically check if someone sent a shutdown signal
Not consume CPU while waiting
# Simplified version of what happens:
@done = false
# Signal handler (set up elsewhere)
Signal.trap("SIGTERM") { @done = true }
# Main loop
while !@done
sleep(2) # Sleep for 2 seconds
# Wake up, check @done again
# If @done=true, exit the loop and shutdown
end
puts "Shutting down gracefully..."
Real-world example:
$ bin/sidekiq
# Process starts, enters the while loop
# Sleeps for 2 seconds, checks @done=false, sleeps again...
# In another terminal:
$ kill -TERM <sidekiq_pid>
# This sets @done=true
# Next time the while loop wakes up, it sees @done=true and exits
2. 🔄 What is loop do in Ruby?
loop do is Ruby’s infinite loop construct:
loop do
puts "This runs forever!"
sleep(1)
end
Equivalent Forms
These are all the same:
# Method 1: loop do
loop do
# code here
end
# Method 2: while true
while true
# code here
end
# Method 3: until false
until false
# code here
end
Breaking Out of Loops
loop do
puts "Enter 'quit' to exit:"
input = gets.chomp
break if input == "quit" # This exits the loop
puts "You said: #{input}"
end
puts "Goodbye!"
In Sidekiq Context
class Sidekiq::Processor
def run
loop do # Infinite loop
process_one_job
# Only exits when:
# 1. Exception is raised (like Sidekiq::Shutdown)
# 2. break is called
# 3. Process is terminated
end
rescue Sidekiq::Shutdown
puts "Worker shutting down gracefully"
end
end
🔍 The Difference in Context
Main Thread (with while and sleep):
# Purpose: Keep process alive, check for shutdown signals
while !@done
sleep(2) # "Lazy waiting" - check every 2 seconds
end
Worker Threads (with loop do):
# Purpose: Continuously process jobs without delay
loop do
job = fetch_job # This blocks until job available
process(job) # Process immediately
# No sleep needed - fetch_job blocks for us
end
sleep pauses for specified seconds – useful for “lazy polling”
while !@done creates a “checkable” loop that can be stopped
loop do creates an infinite loop for continuous processing
Different purposes:
Main thread: “Stay alive and check occasionally”
Worker threads: “Process jobs continuously”
Simple analogy:
Main thread: Like a security guard who checks the building every 2 minutes
Worker threads: Like cashiers who wait for the next customer (blocking until one arrives)
# At this point:
# - Thread 1 is BLOCKED (not consuming CPU)
# - Ruby interpreter parks this thread
# - Other threads continue running normally
# - The thread is "waiting" for Redis to respond
4. What Wakes Up the Block?
Option A: New Job Arrives
# Somewhere else in your Rails app:
SomeJob.perform_later(user_id)
# This does: redis.lpush("queue:default", job_data)
# ↓
# Redis immediately responds to the waiting BRPOP
# ↓
# Thread 1 wakes up with the job data
job = ["queue:default", job_json_data]
Option B: Timeout Reached
# After 2 seconds of waiting:
job = nil # BRPOP returns nil due to timeout
🧵 Thread State Visualization
Before BRPOP:
Thread 1: [RUNNING] ──► Execute redis.brpop(...)
During BRPOP (queues empty):
Thread 1: [BLOCKED] ──► 💤 Waiting for Redis response
Thread 2: [RUNNING] ──► Also calling redis.brpop(...)
Thread 3: [BLOCKED] ──► 💤 Also waiting
Thread 4: [RUNNING] ──► Processing a job
Thread 5: [BLOCKED] ──► 💤 Also waiting
Job arrives via LPUSH:
Thread 1: [RUNNING] ──► Wakes up! Got the job!
Thread 2: [BLOCKED] ──► Still waiting
Thread 3: [BLOCKED] ──► Still waiting
⚡ Why This is Efficient
Blocking vs Polling Comparison
❌ Bad Approach (Polling):
loop do
job = redis.rpop("queue:default") # Non-blocking
if job
process(job)
else
sleep(0.1) # Check again in 100ms
end
end
# Problems:
# - Wastes CPU checking every 100ms
# - Delays job processing by up to 100ms
# - Not scalable with many workers
✅ Good Approach (BRPOP Blocking):
loop do
job = redis.brpop("queue:default", timeout: 2) # Blocking
process(job) if job
end
# Benefits:
# - Zero CPU usage while waiting
# - Instant job processing (no polling delay)
# - Scales to thousands of workers
🛠️ System-Level Explanation
What Happens in the OS
Ruby calls Redis client
Redis client opens TCP socket to Redis server
Sends BRPOP command over socket
Thread calls system sleep() – goes into “waiting” state
OS scheduler removes thread from active CPU queue
Thread doesn’t run until socket receives data
Ruby Process
├── Thread 1 [BLOCKED on socket read]
├── Thread 2 [RUNNING - processing job]
├── Thread 3 [BLOCKED on socket read]
└── Thread 4 [BLOCKED on socket read]
Operating System Scheduler:
- Only schedules Thread 2 for CPU time
- Threads 1,3,4 are "sleeping" - zero CPU usage
📡 Network Level Detail
Client Redis Server
│ │
│────► BRPOP queue:default ─┤
│ │ Check queue...
│ │ Empty!
│ │ Add client to
│ │ waiting list
│ │
│ 💤 BLOCKED │
│ │
│ │ ◄──── LPUSH from Rails app
│ │
│ ◄──── job_data ──────────┤ Wake up waiting client!
│ │
│ Thread RESUMES │
BRPOP literally pauses thread execution at the OS level
Zero CPU consumption during blocking
Instant response when job arrives (no polling delay)
Multiple threads can block simultaneously on different/same queues
Redis manages the waiting list of blocked clients
Timeout prevents infinite blocking if no jobs arrive
This is why Sidekiq is so efficient – workers spend most of their time blocked (consuming zero resources) and instantly wake up when work arrives!
The blocking mechanism is what makes the “always listening” behavior possible without eating up your server’s resources.
How BRPOP is actually implemented? Sidekiq doesn’t implement it directly – it uses the redis gem, which is the standard Redis client for Ruby.
🚀 How redis.brpop is Implemented in Ruby
The Reality: It’s Actually Simple
The Redis gem doesn’t implement BRPOP itself – it delegates to a lower-level client that handles the actual socket communication. Here’s the architecture:
🏗️ The Ruby Implementation Stack
1. High-Level Redis Gem
# In your Sidekiq code
redis.brpop("queue:default", "queue:low", timeout: 2)
2. Redis Gem Delegation
The Redis gem (the one Sidekiq uses) primarily does:
# Simplified version in the Redis gem
def brpop(*keys, **options)
timeout = options[:timeout] || 0
# Convert arguments to Redis protocol format
command = ["BRPOP"] + keys + [timeout]
# Delegate to lower-level client
call(command)
end
3. Lower-Level Client (redis-client)
The actual networking happens in the redis-client gem:
# In redis-client gem
class RedisClient
def call(command, timeout: nil)
# 1. Format command according to RESP protocol
command_string = format_command(command)
# 2. Send to Redis server
@socket.write(command_string)
# 3. READ AND BLOCK HERE!
# This is where the blocking magic happens
response = @socket.read_with_timeout(timeout)
# 4. Parse and return response
parse_response(response)
end
end
🔍 The Critical Blocking Part
Here’s where the blocking actually happens:
# Simplified socket read implementation
def read_with_timeout(timeout)
if timeout && timeout > 0
# Use IO.select to wait for data with timeout
ready = IO.select([@socket], nil, nil, timeout)
if ready
# Data is available, read it
@socket.read_nonblock(4096)
else
# Timeout reached, return nil
nil
end
else
# Block indefinitely until data arrives
@socket.read # THIS BLOCKS THE THREAD
end
end
⚡ The Socket-Level Magic
At the lowest level, it’s just Ruby’s socket operations:
# What actually happens at the OS level
require 'socket'
socket = TCPSocket.new('localhost', 6379)
# Send BRPOP command
socket.write("*4\r\n$5\r\nBRPOP\r\n$13\r\nqueue:default\r\n$9\r\nqueue:low\r\n$1\r\n2\r\n")
# THIS BLOCKS until Redis responds or timeout
result = socket.read # Ruby thread blocks here
socket.close
🧵 Ruby’s Built-in Blocking
The secret sauce: Ruby’s socket.read method is built-in blocking:
Ruby calls the OS: socket.read translates to system calls like recv() or read()
OS blocks the thread: The operating system puts the thread to sleep
Zero CPU usage: Thread consumes no resources while waiting
Instant wake-up: OS wakes thread when data arrives
🎯 Real Implementation Example
Here’s what a simplified BRPOP implementation looks like:
class SimpleRedisClient
def initialize(host, port)
@socket = TCPSocket.new(host, port)
end
def brpop(key, timeout = 0)
# Format Redis command
command = "*3\r\n$5\r\nBRPOP\r\n$#{key.length}\r\n#{key}\r\n$#{timeout.to_s.length}\r\n#{timeout}\r\n"
# Send command
@socket.write(command)
# BLOCK and wait for response
# This is where the magic happens!
response = @socket.read
# Parse response
parse_redis_response(response)
end
private
def parse_redis_response(response)
# Parse Redis RESP protocol
# Return parsed data or nil for timeout
end
end
No Ruby “magic” – just standard socket operations
OS handles the blocking – not Ruby-specific code
Thread sleeps at kernel level – zero CPU usage
IO.select for timeouts – Ruby’s standard approach
RESP protocol – Redis’s simple text protocol
The “blocking” is just Ruby’s normal socket behaviour – when you read from a socket with no data, the thread naturally blocks until data arrives!
This is why BRPOP is so efficient – it leverages the operating system’s built-in ability to efficiently wait for network data without consuming any CPU resources.
Pretty elegant, right? The complexity is all hidden in the OS networking stack, while the Ruby implementation stays remarkably simple! 🎉
Ruby on Rails has always been about developer happiness and productivity. With Rails 7.2, the framework took a significant step forward by including RuboCop as a built-in tool for new applications. This feature continues in Rails 8.0 and represents a major shift in how Rails approaches code quality and consistency.
RuboCop is a powerful static code analyzer, linter, and code formatter for Ruby. It enforces coding standards based on the community Ruby Style Guide and helps developers:
Maintain consistent code style across projects and teams
Identify potential bugs and code smells early
Automatically fix many style violations
Improve code readability and maintainability
Think of RuboCop as your personal code reviewer that never gets tired and always applies the same standards consistently.
📈 What This Means for Rails Developers
The inclusion of RuboCop as a default tool in Rails represents several significant changes:
🎯 Standardization Across the Ecosystem
Consistent code style across Rails applications
Reduced onboarding time for new team members
Easier code reviews with automated style checking
🚀 Improved Developer Experience
No more manual setup for basic linting
Immediate feedback on code quality
Built-in best practices from day one
📚 Educational Benefits
Learning tool for new Ruby developers
Enforcement of Ruby community standards
Gradual improvement of coding skills
⏰ Before Rails 7.2: The Manual Setup Era
🔧 Manual Installation Process
Before Rails 7.2, integrating RuboCop required several manual steps:
# Omakase Ruby styling for Rails
inherit_gem:
rubocop-rails-omakase: rubocop.yml
# Your own specialized rules go here
🔄 Before vs After: Key Differences
Aspect
Before Rails 7.2
After Rails 7.2
🔧 Setup
Manual, time-consuming
Automatic, zero-config
📊 Consistency
Varies by project/team
Standardized omakase style
⏱️ Time to Start
15-30 minutes setup
Immediate
🎯 Configuration
Custom, often overwhelming
Minimal, opinionated
📚 Learning Curve
Steep for beginners
Gentle, guided
🔄 Maintenance
Manual updates needed
Managed by Rails team
⚡ Advantages of Built-in RuboCop
👥 For Development Teams
🎯 Immediate Consistency
No configuration debates – omakase style provides sensible defaults
Faster onboarding for new team members
Consistent code reviews across all projects
🚀 Increased Productivity
Less time spent on style discussions
More focus on business logic
Automated code formatting saves manual effort
🏫 For Learning and Education
📖 Built-in Best Practices
Ruby community standards enforced by default
Immediate feedback on code quality
Educational comments in RuboCop output
🎓 Skill Development
Gradual learning of Ruby idioms
Understanding of performance implications
Code smell detection capabilities
🏢 For Organizations
📈 Code Quality
Consistent standards across all Rails projects
Reduced technical debt accumulation
Easier maintenance of legacy code
💰 Cost Benefits
Reduced code review time
Fewer bugs in production
Faster developer onboarding
🛠️ Working with RuboCop in Rails 7.2+
🚀 Getting Started
1. 🏃♂️ Running RuboCop
# Check your code
./bin/rubocop
# Auto-fix issues
./bin/rubocop -a
# Check specific files
./bin/rubocop app/models/user.rb
# Check with different format
./bin/rubocop --format json
2. 📊 Understanding Output
$ ./bin/rubocop
Inspecting 23 files
.......C..............
Offenses:
app/models/user.rb:15:81: C: Layout/LineLength: Line is too long. [95/80]
def full_name; "#{first_name} #{last_name}"; end
1 file inspected, 1 offense detected, 1 offense autocorrectable
⚙️ Customizing Configuration
🎨 Adding Your Own Rules
Edit .rubocop.yml to add project-specific rules:
# Omakase Ruby styling for Rails
inherit_gem:
rubocop-rails-omakase: rubocop.yml
# Your own specialized rules go here
Metrics/LineLength:
Max: 120
Style/Documentation:
Enabled: false
# Exclude specific files
AllCops:
Exclude:
- 'db/migrate/*'
- 'config/routes.rb'
🔧 Common Customizations
# Allow longer lines in specs
Metrics/LineLength:
Exclude:
- 'spec/**/*'
# Disable specific cops for legacy code
Style/FrozenStringLiteralComment:
Exclude:
- 'app/legacy/**/*'
# Custom naming patterns
Naming/FileName:
Exclude:
- 'lib/tasks/*.rake'
# Begin with defaults
inherit_gem:
rubocop-rails-omakase: rubocop.yml
# Add team-specific rules only when needed
Metrics/ClassLength:
Max: 150 # Team prefers slightly longer classes
2. 🔄 Use Auto-correction Wisely
# Safe auto-corrections
./bin/rubocop -a
# All auto-corrections (review changes!)
./bin/rubocop -A
# Check what would be auto-corrected
./bin/rubocop --auto-correct --dry-run
3. 📈 Gradual Legacy Code Improvement
# Use rubocop_todo.yml for existing code
inherit_from:
- .rubocop_todo.yml
# Generate todo file for legacy code
# $ bundle exec rubocop --auto-gen-config
🛡️ Handling Violations
🎯 Prioritizing Fixes
🔴 High Priority: Security and bug-prone patterns
🟡 Medium Priority: Performance issues
🟢 Low Priority: Style preferences
📝 Selective Disabling
# Disable for specific lines
user_data = some_complex_hash # rubocop:disable Metrics/LineLength
# Disable for blocks
# rubocop:disable Metrics/AbcSize
def complex_method
# Complex but necessary logic
end
# rubocop:enable Metrics/AbcSize
Better AI-generated code following Rails conventions
Consistent output from coding assistants
Improved code suggestions in IDEs
🏢 Industry Impact
📊 Hiring and Onboarding
Faster developer onboarding with consistent standards
Easier code assessment during interviews
Reduced training time for Rails conventions
🔍 Code Review Process
Automated style checking reduces manual review time
Focus on logic rather than formatting
Consistent feedback across different reviewers
📚 Advanced Usage Patterns
🎯 Team-Specific Configurations
# .rubocop.yml for different team preferences
inherit_gem:
rubocop-rails-omakase: rubocop.yml
# Backend team preferences
Metrics/MethodLength:
Max: 15
# Frontend team (dealing with complex views)
Metrics/AbcSize:
Exclude:
- 'app/helpers/**/*'
# QA team (longer test descriptions)
Metrics/LineLength:
Exclude:
- 'spec/**/*'
# Generate detailed reports
./bin/rubocop --format json --out rubocop.json
./bin/rubocop --format html --out rubocop.html
# Focus on specific cop families
./bin/rubocop --only Layout
./bin/rubocop --only Security
./bin/rubocop --only Performance
📝 Conclusion
The inclusion of RuboCop as a built-in tool in Rails 8.0 (starting from 7.2) represents a significant evolution in the Rails ecosystem. This change brings numerous benefits:
📊 Consistent code quality across the Rails community
📚 Educational benefits for developers at all levels
⚡ Improved productivity through automation
🎨 Balanced approach between opinionated defaults and flexibility
🔮 Looking Forward
As the Rails community adapts to this change, we can expect:
Better code consistency across open-source Rails projects
Improved developer experience for newcomers
Enhanced tooling integration throughout the ecosystem
Continued evolution of the omakase philosophy
💡 Final Recommendations
🎯 Embrace the defaults initially – they’re well-considered
📚 Learn from violations rather than just fixing them
🔄 Customize gradually based on team needs
🤝 Use it as a teaching tool for junior developers
📈 Monitor improvements in code quality over time
The built-in RuboCop integration exemplifies Rails’ commitment to developer happiness and productivity. By providing sensible defaults while maintaining flexibility, Rails continues to evolve as a framework that scales with teams and projects of all sizes.
Whether you’re starting a new Rails project or maintaining an existing one, RuboCop’s integration offers an opportunity to improve code quality and developer experience with minimal effort. Embrace the omakase philosophy, customize where needed, and enjoy cleaner, more consistent Ruby code! 🎉
Have you started using RuboCop with Rails 8.0? Share your experiences and customizations in the comments below!
I made a mistake of integrating the sessions with Order and Order items model (I used the help of Co-piolet for improvement). I have only written the test cases for sessions. Why I made this mistake? Because for last some days the development was not happening in our design_studio project. So I was curious to do so many things at a time and I cannot control myself 🙂
Now what’s next?
Let’s solve the test cases issues. First I cannot get ‘why this test cases for Rate limit issue is happening’. I have to research on this. I want to try Cursor – how it works with these kind of scenarios. Cursor provide me details about exact issue in our test cases and updated for me. I was happy that I saved some time.
Let’s see What is the findings of cursor:
The current test case has few issues:
It’s testing for 11 attempts, but the rate limit is set to 10 attempts. We should test that the 11th attempt is rate limited, but also verify that the first 10 attempts work as expected.
We should verify that the rate limiting is time-based (within 1 minute) by testing that after waiting, the rate limit resets.
Fix the test case:
Cursor updated the test case to properly test the rate limiting functionality. Here’s what the improved test does:
First, it makes 10 attempts and verifies that each attempt gets the normal “invalid credentials” response
Then it makes the 11th attempt and verifies that it gets rate limited with the “Try again later” message
Finally, it uses Rails’ travel helper to move forward in time past the rate limit window (1 minute + 1 second) and verifies that the rate limit has been reset by making another attempt
This test now properly verifies:
The rate limit threshold (10 attempts)
The rate limit behavior (redirect with “Try again later” message)
The rate limit duration (1 minute)
The rate limit reset after the time window expires
The test is now more thorough and matches the actual implementation in the SessionsController.
Run the test case with the fix:
Failure:
SessionsControllerTest#test_should_rate_limit_login_attempts [test/controllers/sessions_controller_test.rb:34]:
--- expected
+++ actual
@@ -1 +1 @@
-"Try again later."
+"Try another email address or password."
the problem is that the rate limiting is happening at the controller level using rate_limit, but our test isn’t properly simulating real-world timing. Let me modify the test to ensure we’re making the requests within the 1-minute window and properly testing the rate limiting.
We fixed it and still the issues are not solved:
# Running:
F
Failure:
SessionsControllerTest#test_should_rate_limit_login_attempts [test/controllers/sessions_controller_test.rb:36]:
--- expected
+++ actual
@@ -1 +1 @@
-"Try again later."
+"Try another email address or password."
bin/rails test test/controllers/sessions_controller_test.rb:23
The issue may be with our SessionsControllerrate_limit directive. That is not working in test environment. I had this doubt. Let’s see what cursor tell us regarding this:
Looking at the SessionsController, the rate limiting is implemented using Rails’ rate_limit macro, but it seems the rate limiting might not be working as expected in the test environment. Let’s try to debug this by checking if we need to enable rate limiting in the test environment or if there’s a different approach needed.
Cursor suggested Rails cache setup and wipe out cache:
require "test_helper"
class SessionsControllerTest < ActionDispatch::IntegrationTest
setup do
# Use memory store for rate limiting in tests
Rails.cache = ActiveSupport::Cache::MemoryStore.new
end
teardown do
Rails.cache.clear
end
......
The test environment is configured to use :null_store for caching, which means rate limiting won’t work. Let’s modify the test environment configuration:
Changed the test environment’s cache store from :null_store to :memory_store to ensure rate limiting works properly
Added a consistent IP address in the test requests using headers: { REMOTE_ADDR: “192.168.1.1” } since rate limiting is typically done based on the client’s IP address
The test should now work correctly because:
We have proper caching enabled in the test environment
We’re using a consistent IP address for all requests, which is what rate limiting typically uses to track requests
We’re still maintaining the time window with travel_to and travel
The cache is cleared between tests to ensure a clean state
Try running the test again – it should now properly detect when the rate limit is exceeded on the 11th request.
Running 5 tests in a single process (parallelization threshold is 50)
Run options: --seed 55394
# Running:
.
Finished in 1.222473s, 0.8180 runs/s, 28.6305 assertions/s.
1 runs, 35 assertions, 0 failures, 0 errors, 0 skips
Coverage report generated for Unit Tests to /Users/abhilash/rails/design_studio/public/coverage.
Line Coverage: 21.37% (81 / 379)
Works!! Cursor – you beauty.
Let us see why the fix worked:
The main issue was that the test environment was using :null_store for caching, which effectively disabled all caching. Since Rails’ rate limiting feature relies on caching to track request counts, it wasn’t working properly.
By changing to :memory_store, we enabled proper caching in the test environment, allowing the rate limiting to track requests.
Adding the consistent IP address (REMOTE_ADDR: “192.168.1.1”) in the test requests was also important because Rails’ rate limiting typically uses the client’s IP address as part of the cache key to track requests per client.
The test structure ensures clean state by:
Using setup to initialize a fresh cache store for each test
Using teardown to clear the cache after each test
Using travel_to to ensure consistent timing for rate limit windows
Using consistent IP addresses for request tracking
This is a good example of how testing rate limiting requires careful consideration of the entire environment, including caching, timing, and request attributes. The test now properly verifies that:
Users can make up to 10 attempts within a minute
The 11th attempt gets rate limited
After waiting for a minute, they can try again
I may need some more time to get the fact that: “Rails’ rate limiting feature relies on caching to track request counts”. Here is the importance of AI tool like cursor. It saved a lot of my debugging time.
When building a Rails API app, you typically need token-based authentication instead of cookie-based sessions (which are more common in full-stack Rails apps). Here are the most common authentication mechanisms you can use in a Rails API-only application:
How it works: After login, the server issues a JWT token which the client must include in the Authorization header (Bearer <token>) in subsequent requests.
Pros:
Stateless, scalable.
Widely supported across mobile and frontend frameworks.
Cons:
Tokens can’t be invalidated easily without extra measures (e.g., a blacklist).
b. Token-based Auth with Devise + TokenAuthenticatable
POST /login
Content-Type: application/json
{
"email": "test@example.com",
"password": "password123"
}
Response:
{ "token": "eyJhbGciOi..." }
Step 3: Use Token in Authenticated Request
GET /profile
Authorization: Bearer eyJhbGciOi...
🔒 Extras You Might Add Later
Token expiration errors
Refresh tokens
Token revocation (e.g., a blacklist table)
Roles/permissions inside the token (e.g., admin claims)
Let’s now write RSpec tests for the JWT-based authentication flow we just set up in your Rails API app.
Assumptions
You already have:
A User model with email and password_digest
An AuthController with login
A UsersController with a protected profile action
JWT auth logic in JsonWebToken
🔧 Step 1: Add RSpec & Factory Bot
In your Gemfile (if not already added):
group :development, :test do
gem 'rspec-rails'
gem 'factory_bot_rails'
end
group :test do
gem 'faker'
end
Then install:
bundle install
rails generate rspec:install
🏭 Step 2: Setup Factory for User
spec/factories/users.rb:
FactoryBot.define do
factory :user do
email { Faker::Internet.email }
password { 'password123' }
password_confirmation { 'password123' }
end
end
🧪 Step 3: Auth Request Specs
spec/requests/auth_spec.rb:
require 'rails_helper'
RSpec.describe 'Authentication', type: :request do
let!(:user) { create(:user, password: 'password123') }
describe 'POST /login' do
context 'with valid credentials' do
it 'returns a JWT token' do
post '/login', params: { email: user.email, password: 'password123' }
expect(response).to have_http_status(:ok)
expect(JSON.parse(response.body)).to include('token')
end
end
context 'with invalid credentials' do
it 'returns unauthorized' do
post '/login', params: { email: user.email, password: 'wrong' }
expect(response).to have_http_status(:unauthorized)
expect(JSON.parse(response.body)).to include('error')
end
end
end
end
🔒 Step 4: Profile (Protected) Request Specs
spec/requests/users_spec.rb:
require 'rails_helper'
RSpec.describe 'Users', type: :request do
let!(:user) { create(:user) }
let(:token) { JsonWebToken.encode(user_id: user.id) }
describe 'GET /profile' do
context 'with valid token' do
it 'returns user profile' do
get '/profile', headers: { 'Authorization' => "Bearer #{token}" }
expect(response).to have_http_status(:ok)
json = JSON.parse(response.body)
expect(json['email']).to eq(user.email)
end
end
context 'without token' do
it 'returns unauthorized' do
get '/profile'
expect(response).to have_http_status(:unauthorized)
end
end
context 'with invalid token' do
it 'returns unauthorized' do
get '/profile', headers: { 'Authorization' => 'Bearer invalid.token' }
expect(response).to have_http_status(:unauthorized)
end
end
end
end
📦 Final Tips
Run tests with: bundle exec rspec
You can stub JsonWebToken.decode in unit tests if needed to isolate auth logic.
When choosing between RSpec and Minitest for writing tests in a Ruby on Rails application, both are solid options, but the best choice depends on your project goals, team preferences, and ecosystem alignment.
♦️ Use RSpec if:
You want a rich DSL for expressive, readable tests (describe, context, it, etc.).
You’re working on a large project or with a team familiar with RSpec.
You want access to a larger ecosystem of gems/plugins (e.g., FactoryBot, Shoulda Matchers).
You like writing spec-style tests and separating tests by type (spec/models, spec/controllers, etc.).
Example RSpec syntax:
describe User do
it "is valid with a name and email" do
user = User.new(name: "Alice", email: "alice@example.com")
expect(user).to be_valid
end
end
♦️ Use Minitest if:
You prefer simplicity and speed — it’s built into Rails and requires no setup.
You value convention over configuration and a more Ruby-like test style.
You’re working on a small-to-medium project or want to avoid extra dependencies.
You like tests integrated with rails test without RSpec’s additional structure.
Example Minitest syntax:
class UserTest < ActiveSupport::TestCase
test "is valid with a name and email" do
user = User.new(name: "Alice", email: "alice@example.com")
assert user.valid?
end
end
🚦Recommendation:
Go with RSpec if you want a full-featured testing suite, lots of documentation, and are okay with learning a custom DSL.
Stick with Minitest if you want fast boot time, minimal dependencies, and simpler syntax.
Below is a side-by-side comparison of RSpec and Minitest in a Rails 8 context. For each aspect—setup, syntax, assertions, fixtures/factories, controller tests, etc.—you’ll see how you’d do the same thing in RSpec (left) versus Minitest (right). Wherever possible, the examples mirror each other so you can quickly spot the differences.
1. Setup & Configuration
Aspect
RSpec
Minitest
Gem inclusion
Add to your Gemfile: ruby<br>group :development, :test do<br> gem 'rspec-rails', '~> 6.0' # compatible with Rails 8<br>end<br>Then run:bash<br>bundle install<br>rails generate rspec:install<br>This creates spec/ directory with spec/spec_helper.rb and spec/rails_helper.rb.
Built into Rails. No extra gems required. When you generate your app, Rails already configures Minitest.By default you have test/ directory with test/test_helper.rb.
spec/support/... (you can require them via rails_helper.rb)
test/helpers/... (auto-loaded via test_helper.rb)
3. Basic Model Validation Example
RSpec (spec/models/user_spec.rb)
# spec/models/user_spec.rb
require 'rails_helper'
RSpec.describe User, type: :model do
context "validations" do
it "is valid with a name and email" do
user = User.new(name: "Alice", email: "alice@example.com")
expect(user).to be_valid
end
it "is invalid without an email" do
user = User.new(name: "Alice", email: nil)
expect(user).not_to be_valid
expect(user.errors[:email]).to include("can't be blank")
end
end
end
Minitest (test/models/user_test.rb)
# test/models/user_test.rb
require "test_helper"
class UserTest < ActiveSupport::TestCase
test "valid with a name and email" do
user = User.new(name: "Alice", email: "alice@example.com")
assert user.valid?
end
test "invalid without an email" do
user = User.new(name: "Alice", email: nil)
refute user.valid?
assert_includes user.errors[:email], "can't be blank"
end
end
4. Using Fixtures vs. Factories
RSpec (with FactoryBot)
Gemfile: group :development, :test do gem 'rspec-rails', '~> 6.0' gem 'factory_bot_rails' end
Factory definition (spec/factories/users.rb): # spec/factories/users.rb FactoryBot.define do factory :user do name { "Bob" } email { "bob@example.com" } end end
Spec using factory: # spec/models/user_spec.rb require 'rails_helper' RSpec.describe User, type: :model do it "creates a valid user via factory" do user = FactoryBot.build(:user) expect(user).to be_valid end end
Minitest (with Fixtures or Minitest Factories)
Default fixture (test/fixtures/users.yml): alice: name: Alice email: alice@example.com bob: name: Bob email: bob@example.com
Test using fixture: # test/models/user_test.rb require "test_helper" class UserTest < ActiveSupport::TestCase test "fixture user is valid" do user = users(:alice) assert user.valid? end end
(Optional) Using minitest-factory_bot: If you prefer factory style, you can add gem 'minitest-factory_bot', define factories similarly under test/factories, and then: # test/models/user_test.rb require "test_helper" class UserTest < ActiveSupport::TestCase include FactoryBot::Syntax::Methods test "factory user is valid" do user = build(:user) assert user.valid? end end
5. Assertions vs. Expectations
Category
RSpec (expectations)
Minitest (assertions)
Check truthiness
expect(some_value).to be_truthy
assert some_value
Check false/nil
expect(value).to be_falsey
refute value
Equality
expect(actual).to eq(expected)
assert_equal expected, actual
Inclusion
expect(array).to include(item)
assert_includes array, item
Change/Count difference
expect { action }.to change(Model, :count).by(1)
assert_difference 'Model.count', 1 do <br> action<br>end
# spec/models/post_spec.rb
require 'rails_helper'
RSpec.describe Post, type: :model do
it "increments Post.count by 1 when created" do
expect { Post.create!(title: "Hello", content: "World") }
.to change(Post, :count).by(1)
end
end
Minitest:
# test/models/post_test.rb
require "test_helper"
class PostTest < ActiveSupport::TestCase
test "creation increases Post.count by 1" do
assert_difference 'Post.count', 1 do
Post.create!(title: "Hello", content: "World")
end
end
end
6. Controller (Request/Integration) Tests
6.1 Controller‐Level Test
RSpec (spec/controllers/users_controller_spec.rb)
# spec/controllers/users_controller_spec.rb
require 'rails_helper'
RSpec.describe UsersController, type: :controller do
let!(:user) { FactoryBot.create(:user) }
describe "GET #show" do
it "returns http success" do
get :show, params: { id: user.id }
expect(response).to have_http_status(:success)
end
it "assigns @user" do
get :show, params: { id: user.id }
expect(assigns(:user)).to eq(user)
end
end
describe "POST #create" do
context "with valid params" do
let(:valid_params) { { user: { name: "Charlie", email: "charlie@example.com" } } }
it "creates a new user" do
expect {
post :create, params: valid_params
}.to change(User, :count).by(1)
end
it "redirects to user path" do
post :create, params: valid_params
expect(response).to redirect_to(user_path(User.last))
end
end
context "with invalid params" do
let(:invalid_params) { { user: { name: "", email: "" } } }
it "renders new template" do
post :create, params: invalid_params
expect(response).to render_template(:new)
end
end
end
end
# test/controllers/users_controller_test.rb
require "test_helper"
class UsersControllerTest < ActionDispatch::IntegrationTest
setup do
@user = users(:alice) # from fixtures
end
test "should get show" do
get user_url(@user)
assert_response :success
assert_not_nil assigns(:user) # note: assigns may need enabling in Rails 8
end
test "should create user with valid params" do
assert_difference 'User.count', 1 do
post users_url, params: { user: { name: "Charlie", email: "charlie@example.com" } }
end
assert_redirected_to user_url(User.last)
end
test "should render new for invalid params" do
post users_url, params: { user: { name: "", email: "" } }
assert_response :success # renders :new with 200 status by default
assert_template :new
end
end
Note:
In Rails 8, controller tests are typically integration tests (ActionDispatch::IntegrationTest) rather than old‐style unit tests. RSpec’s type: :controller still works, but you can also use type: :request (see next section).
assigns(...) is disabled by default in modern Rails controller tests. In Minitest, you might enable it or test via response body or JSON instead.
6.2 Request/Integration Test
RSpec Request Spec (spec/requests/users_spec.rb)
# spec/requests/users_spec.rb
require 'rails_helper'
RSpec.describe "Users API", type: :request do
let!(:user) { FactoryBot.create(:user) }
describe "GET /api/v1/users/:id" do
it "returns the user in JSON" do
get api_v1_user_path(user), as: :json
expect(response).to have_http_status(:ok)
json = JSON.parse(response.body)
expect(json["id"]).to eq(user.id)
expect(json["email"]).to eq(user.email)
end
end
describe "POST /api/v1/users" do
let(:valid_params) { { user: { name: "Dana", email: "dana@example.com" } } }
it "creates a user" do
expect {
post api_v1_users_path, params: valid_params, as: :json
}.to change(User, :count).by(1)
expect(response).to have_http_status(:created)
end
end
end
Minitest Integration Test (test/integration/users_api_test.rb)
# test/integration/users_api_test.rb
require "test_helper"
class UsersApiTest < ActionDispatch::IntegrationTest
setup do
@user = users(:alice)
end
test "GET /api/v1/users/:id returns JSON" do
get api_v1_user_path(@user), as: :json
assert_response :success
json = JSON.parse(response.body)
assert_equal @user.id, json["id"]
assert_equal @user.email, json["email"]
end
test "POST /api/v1/users creates a user" do
assert_difference 'User.count', 1 do
post api_v1_users_path, params: { user: { name: "Dana", email: "dana@example.com" } }, as: :json
end
assert_response :created
end
end
Slower boot time because it loads extra files (rails_helper.rb, support files, matchers).
Rich DSL can make tests slightly slower, but you get clearer, more descriptive output.
Minitest
Faster boot time since it’s built into Rails and has fewer abstractions.
Ideal for a smaller codebase or when you want minimal overhead.
Benchmarks: While exact numbers vary, many Rails 8 teams report ~20–30% faster test suite runtime on Minitest vs. RSpec for comparable test counts. If speed is critical and test suite size is moderate, Minitest edges out.
10. Community, Ecosystem & Plugins
Feature
RSpec
Minitest
Popularity
By far the most popular Rails testing framework⸺heavily used, many tutorials.
Standard in Rails. Fewer third-party plugins than RSpec, but has essential ones (e.g., minitest-rails, minitest-factory_bot).
Common plugins/gems
• FactoryBot• Shoulda Matchers (for concise model validations)• Database Cleaner (though Rails 8 encourages use_transactional_tests)• Capybara built-in support
Abundant (RSPEC official guides, many blog posts, StackOverflow).
Good coverage in Rails guides; fewer dedicated tutorials but easy to pick up if you know Ruby.
CI Integration
Excellent support in CircleCI, GitHub Actions, etc. Many community scripts to parallelize RSpec.
Equally easy to integrate; often faster out of the box due to fewer dependencies.
11. Example: Complex Query Test (Integration of AR + Custom Validation)
RSpec
# spec/models/order_spec.rb
require 'rails_helper'
RSpec.describe Order, type: :model do
describe "scopes and validations" do
before do
@user = FactoryBot.create(:user)
@valid_attrs = { user: @user, total_cents: 1000, status: "pending" }
end
it "finds only completed orders" do
FactoryBot.create(:order, user: @user, status: "completed")
FactoryBot.create(:order, user: @user, status: "pending")
expect(Order.completed.count).to eq(1)
end
it "validates total_cents is positive" do
order = Order.new(@valid_attrs.merge(total_cents: -5))
expect(order).not_to be_valid
expect(order.errors[:total_cents]).to include("must be greater than or equal to 0")
end
end
end
Minitest
# test/models/order_test.rb
require "test_helper"
class OrderTest < ActiveSupport::TestCase
setup do
@user = users(:alice)
@valid_attrs = { user: @user, total_cents: 1000, status: "pending" }
end
test "scope .completed returns only completed orders" do
Order.create!(@valid_attrs.merge(status: "completed"))
Order.create!(@valid_attrs.merge(status: "pending"))
assert_equal 1, Order.completed.count
end
test "validates total_cents is positive" do
order = Order.new(@valid_attrs.merge(total_cents: -5))
refute order.valid?
assert_includes order.errors[:total_cents], "must be greater than or equal to 0"
end
end
12. When to Choose Which?
Choose RSpec if …
You want expressive, English-like test descriptions (describe, context, it).
Your team is already comfortable with RSpec.
You need a large ecosystem of matchers/plugins (e.g., shoulda-matchers, faker, etc.).
You prefer separating specs into spec/ with custom configurations in rails_helper.rb and spec_helper.rb.
Choose Minitest if …
You want zero additional dependencies—everything is built into Rails.
You value minimal configuration and convention over configuration.
You need faster test suite startup and execution.
Your tests are simple enough that a minimal DSL is sufficient.
13. 📋 Summary Table
Feature
RSpec
Minitest
Built-in with Rails
No (extra gem)
Yes
DSL Readability
“describe/context/it” blocks → very readable
Plain Ruby test classes & methods → idiomatic but less English-like
Ecosystem & Plugins
Very rich (FactoryBot, Shoulda, etc.)
Leaner, but you can add factories & reporters if needed
Setup/Boot Time
Slower (loads extra config & DSL)
Faster (built-in)
Fixtures vs. Factory preference
FactoryBot (by convention)
Default YAML fixtures or optionally minitest-factory_bot
Integration Test Support
Built-in type: :request
Built-in ActionDispatch::IntegrationTest
Community Adoption
More widely adopted for large Rails teams
Standard for many smaller Rails projects
✍️ Final Note
If you’re just starting out and want something up and running immediately—Minitest is the simplest path since it requires no extra gems. You can always add more complexity later (e.g., add minitest-factory_bot or minitest-reporters).
If you plan to write a lot of tests—model validations, request specs, feature specs, etc.—with very expressive descriptions (and you don’t mind a slightly longer boot time), RSpec tends to be the de facto choice in many Rails codebases.
Feel free to pick whichever aligns best with your team’s style. Both ecosystems are mature and well-documented.
In a Rails Gemfile, the require: false option tells Bundler not to automatically load the gem when your Rails application starts. Here’s what it means and when to use it:
What It Does
gem 'some_gem', require: false
Without require: false: The gem is automatically required (loaded) when your Rails app boots
With require: false: The gem is installed but won’t be loaded until you explicitly require it
When to Use It
Performance Optimization: For gems you don’t need in all environments (like development-only tools)
Conditional Loading: When you only need a gem in specific circumstances
Reduced Memory Usage: Avoids loading unnecessary gems into memory
Avoid Naming Conflicts: If a gem might conflict with others when loaded
Example Usage
# Only load in development
group :development do
gem 'brakeman', require: false
end
# Load manually when needed
gem 'nokogiri', require: false
# Then in your code:
def parse_xml
require 'nokogiri'
# use Nokogiri...
end
Common Gems That Use This
Testing tools (RSpec, Cucumber)
Performance monitoring tools
Debugging tools (byebug, pry)
Gems used only in rake tasks
Remember that without require: false, Bundler will automatically require the gem, which is the default behavior for most gems in your application.